║▄ČÓĢr(sh©¬)║“╬ęéāČ╝Ģ■(hu©¼)ī”(du©¼)M0Ż¼M0+,M3,M4Ż¼M7Ż¼arm7Ż¼arm9Ż¼CORTEX-AŽĄ┴ąŻ¼╗“š▀šf(shu©Ł)AVR,51Ż¼PICĄ╚Ż¼ę╗Ņ^ņF╦«Ż¼ų╗ų¬Ą└╩Ū╝▄śŗ(g©░u)Ż¼▓╗ų¬Ą└Š▀¾w╩Ū╩▓├┤Ż¼ėą──ą®▓╗═¼Ż┐Į±╠ņ▓ķ┴╦ą®┘Y┴ŽŻ¼üĒ(l©ói)ĮŌĮŌ╗¾Ż¼▓╗╩Ū║▄įö╝Ü(x©¼)Ż¼Ą½ī”(du©¼)┤╦ėąéĆ(g©©)┤¾¾w┴╦ĮŌĪŻį█Ž╚üĒ(l©ói)«ö(d©Īng)Ž┬ūŅ╗Ą─ARM░╔
1.ARM
ARM╝┤ęįėóć°(gu©«)ARMŻ©Advanced RISC MachinesŻ®╣½╦ŠĄ─ā╚(n©©i)║╦ąŠŲ¼ū„×ķCPUŻ¼═¼Ģr(sh©¬)ĖĮ╝ėŲõ╦¹═Ōć·╣”─▄Ą─ŪČ╚ļ╩Įķ_(k©Īi)░l(f©Ī)░ÕŻ¼ė├ęįįu(p©¬ng)╣└ā╚(n©©i)║╦ąŠŲ¼Ą─╣”─▄║═čą░l(f©Ī)Ė„┐Ų╝╝ŅÉ(l©©i)Ų¾śI(y©©)Ą─«a(ch©Żn)ŲĘ.
ARM ╬ó╠Ä└ĒŲ„─┐Ū░░³└©Ž┬├µÄūéĆ(g©©)ŽĄ┴ąŻ¼ęį╝░Ųõ╦³ÅS╔╠╗∙ė┌ ARM ¾wŽĄĮY(ji©”)śŗ(g©░u)Ą─╠Ä└ĒŲ„Ż¼│²┴╦Š▀ėąARM ¾wŽĄĮY(ji©”)śŗ(g©░u)Ą─╣▓═¼╠ž³c(di©Żn)ęį═ŌŻ¼├┐ę╗éĆ(g©©)ŽĄ┴ąĄ─ ARM ╬ó╠Ä└ĒŲ„Č╝ėąĖ„ūįĄ─╠ž³c(di©Żn)║═æ¬(y©®ng)ė├ŅI(l©½ng)ė“ĪŻ
ŻŁ ARM7 ŽĄ┴ą
ŻŁ ARM9 ŽĄ┴ą
ŻŁ ARM9E ŽĄ┴ą
ŻŁ ARM10E ŽĄ┴ą
ŻŁ ARM11ŽĄ┴ą
ŻŁ Cortex ŽĄ┴ą
ŻŁ SecurCore ŽĄ┴ą
ŻŁ OptimoDE Data Engines
ŻŁ IntelĄ─Xscale
ŻŁ IntelĄ─StrongARM ARM11ŽĄ┴ą
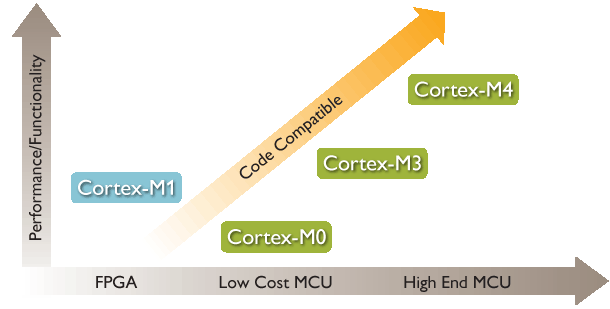
2. Cortex ŽĄ┴ą
32╬╗RISCCPUķ_(k©Īi)░l(f©Ī)ŅI(l©½ng)ė“ųą▓╗öÓ╚ĪĄ├═╗ŲŲŻ¼ŲõįO(sh©©)ėŗ(j©¼)Ą─╬ó╠Ä└ĒŲ„ĮY(ji©”)śŗ(g©░u)ęčĮø(j©®ng)Å─v3░l(f©Ī)š╣ĄĮ¼F(xi©żn)į┌Ą─v7ĪŻCortexŽĄ┴ą╠Ä└ĒŲ„╩Ū╗∙ė┌ARMv7╝▄śŗ(g©░u)Ą─Ż¼
Ęų×ķCortex-MĪóCortex-R║═Cortex-A╚²ŅÉ(l©©i)ĪŻė╔ė┌æ¬(y©®ng)ė├ŅI(l©½ng)ė“Ą─▓╗═¼Ż¼╗∙ė┌v7╝▄śŗ(g©░u)Ą─Cortex╠Ä└ĒŲ„ŽĄ┴ą╦∙▓╔ė├Ą─╝╝ąg(sh©┤)ę▓▓╗ŽÓ═¼ĪŻ╗∙ė┌v7AĄ─ĘQ×ķ“Cortex-AŽĄ┴ąĪŻ
Ė▀ąį─▄Ą─Cortex-A15Īó┐╔╔ņ┐sĄ─Cortex-A9ĪóĮø(j©®ng)▀^(gu©░)╩ął÷(ch©Żng)“×(y©żn)ūCĄ─Cortex-A8╠Ä└ĒŲ„ęį╝░Ė▀ą¦Ą─Cortex-A7║═Cortex-A5╠Ä└ĒŲ„Š∙╣▓ŽĒ═¼ę╗¾wŽĄĮY(ji©”)śŗ(g©░u)Ż¼ę“┤╦Š▀ėą═Ļš¹Ą─æ¬(y©®ng)ė├╝µ╚▌ąįŻ¼ų¦│ųé„Įy(t©»ng)Ą─ARMĪóThumbųĖ┴Ņ╝»
║═ą┬į÷Ą─Ė▀ąį─▄Šo£Éą═Thumb-2ųĖ┴Ņ╝»ĪŻ
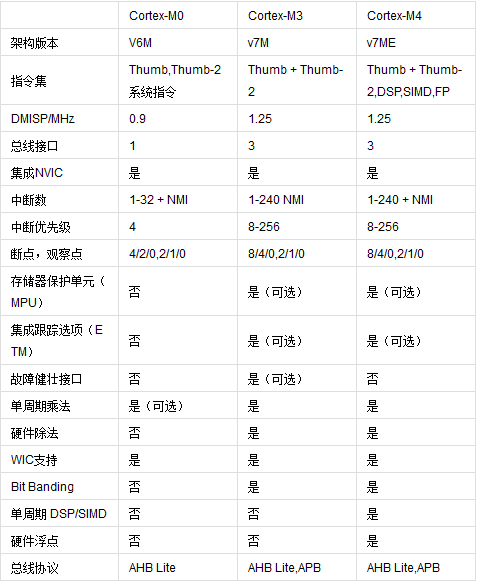
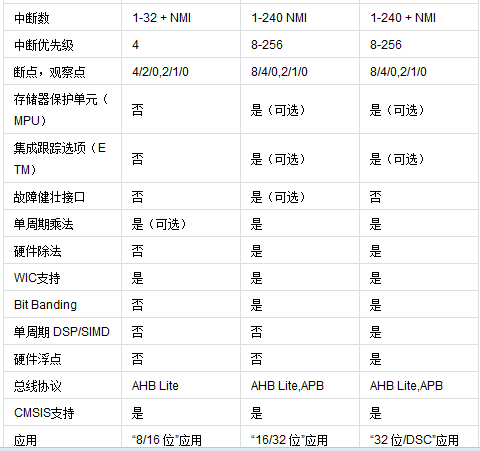
1Cortex-MŽĄ┴ą
Cortex-MŽĄ┴ąėų┐╔Ęų×ķCortex-M0ĪóCortex-M0+ĪóCortex-M3ĪóCortex-M4Ż╗
2Cortex-RŽĄ┴ą
Cortex-RŽĄ┴ąĘų×ķCortex-R4ĪóCortex-R5ĪóCortex-R7Ż╗
3Cortex-A ŽĄ┴ą
Cortex-AŽĄ┴ąĘų×ķCortex-A5ĪóCortex-A7ĪóCortex-A8ĪóCortex-A9ĪóCortex-A15ĪóCortex-A50Ą╚ Ż¼═¼śėę▓Š═ėą┴╦ī”(du©¼)æ¬(y©®ng)ā╚(n©©i)║╦Ą─Cortex-M0ķ_(k©Īi)░l(f©Ī)░ÕĪóCortex-A5ķ_(k©Īi)░l(f©Ī)░ÕĪóCortex-A8ķ_(k©Īi)░l(f©Ī)░ÕĪóCortex-A9ķ_(k©Īi)░l(f©Ī)░ÕĪó
Cortex-R4ķ_(k©Īi)░l(f©Ī)░ÕĄ╚Ą╚ĪŻ
4░ļī¦(d©Żo)¾w
ė╔ė┌ARM╣½╦Šų╗ī”(du©¼)═Ō╠ß╣®ARMā╚(n©©i)║╦Ż¼Ė„┤¾ÅS╔╠į┌╩┌ÖÓ(qu©ón)ĖČ┘M(f©©i)╩╣ė├ARMā╚(n©©i)║╦Ą─╗∙ĄA(ch©│)╔Žčą░l(f©Ī)╔·«a(ch©Żn)Ė„ūįĄ─ąŠŲ¼Ż¼ą╬│╔┴╦ŪČ╚ļ╩ĮARM CPUĄ─┤¾╝ę═źŻ¼╠ß╣®▀@ą®ā╚(n©©i)║╦ąŠŲ¼Ą─ÅS╔╠ėąAtmelĪóTIĪó’w╦╝┐©Ā¢ĪóNXPĪóSTĪó║═╚²ąŪĄ╚ĪŻ
Cortex-M╝µ╚▌╠žąį
ĪĪĪĪ×ķ┴╦─▄ū÷ĄĮCortex-M▄ø╝■ųžė├Ż¼ARM╣½╦Šį┌įO(sh©©)ėŗ(j©¼)Cortex-M╠Ä└ĒŲ„Ģr(sh©¬)×ķŲõ┘xėĶ┴╦╠Ä└ĒŲ„Ž“Ž┬╝µ╚▌Īó▄ø╝■Č■▀M(j©¼n)ųŲŽ“╔Ž╝µ╚▌╠žąįĪŻ
ĪĪĪĪ╩ūŽ╚┐┤╩▓├┤╩ŪČ■▀M(j©¼n)ųŲ╝µ╚▌Ż¼▀@éĆ(g©©)╠žąįų„ę¬╩Ūßśī”(du©¼)▄ø╝■Č°čįŻ¼▀@└’ųĖĄ─╩Ū«ö(d©Īng)─│▄ø╝■(│╠ą“)ę└┘ćĄ─Ņ^╬─╝■╗“Äņ(k©┤)╬─╝■Ęųäe╔²╝ē(j©¬)Ģr(sh©¬)Ż¼▄ø╝■╣”─▄▓╗╩▄ė░ĒæĪŻę¬ū÷ĄĮČ■▀M(j©¼n)ųŲ╝µ╚▌Ż¼▒╗▄ø╝■╦∙ę└┘ćĄ─Ņ^╬─╝■╗“Äņ(k©┤)╬─╝■╔²╝ē(j©¬)Ģr(sh©¬)▒žĒÜ╩ŪČ■▀M(j©¼n)ųŲ╝µ╚▌Ą─ĪŻ
ĪĪĪĪ─Ū├┤╩▓├┤ėų╩ŪŽ“╔Ž╝µ╚▌Ż¼Ž“╔Ž╝µ╚▌ėųĮąŽ“Ū░╝µ╚▌Ż¼ųĖĄ─╩Ūį┌▌^Ą═░µ▒Š╠Ä└ĒŲ„╔ŽŠÄūgĄ─▄ø╝■┐╔ęįį┌▌^Ė▀░µ▒Š╠Ä└ĒŲ„╔Žł╠(zh©¬)ąąĪŻ
ĪĪĪĪĖ·Ž“╔Ž╝µ╚▌ŽÓī”(du©¼)Ą─┴Ēę╗éĆ(g©©)Ė┼─ŅĮąŽ“Ž┬╝µ╚▌Ż¼Ž“Ž┬╝µ╚▌ėųĮąŽ“║¾╝µ╚▌Ż¼ųĖĄ─╩Ū▌^Ė▀░µ▒Š╠Ä└ĒŲ„┐╔ęįš²┤_▀\(y©┤n)ąąį┌▌^Ą═░µ▒Š╠Ä└ĒŲ„╔ŽŠÄūgĄ─▄ø╝■ĪŻ
ĪĪĪĪ╦∙ęįŲõīŹ(sh©¬)╝╚┐╔ęįė├Ž“╔Ž╝µ╚▌Ż¼ę▓┐╔ęįė├Ž“Ž┬╝µ╚▌üĒ(l©ói)ą╬╚▌Cortex-M╠žąįŻ¼ų╗▓╗▀^(gu©░)├Ķ╩÷Ą─ų„šZ(y©│)▓╗ę╗śėŻ¼╬ęéā┐╔ęįšf(shu©Ł)Cortex-M│╠ą“╩ŪŽ“╔Ž╝µ╚▌Ą─Ż¼ę▓┐╔ęįšf(shu©Ł)Cortex-M╠Ä└ĒŲ„╩ŪŽ“Ž┬╝µ╚▌Ą─ĪŻ
ĪĪĪĪŠ▀¾wĄĮCortex-M╠Ä└ĒŲ„Ģr(sh©¬)Ż¼▀@éĆ(g©©)╝µ╚▌╠žąį▒Ē¼F(xi©żn)×ķŻ║
- Å─╠Ä└ĒŲ„ĮŪČ╚┐┤Ż║CM0ųĖ┴Ņ╝»║═╣”─▄─ŻēK╩ŪūŅŠ½║å(ji©Żn)Ą─Ż¼CM7ųĖ┴Ņ╝»║═╣”─▄─ŻēK╩ŪūŅžSĖ╗Ą─ĪŻ▓╗┤µį┌Ą═░µ▒Š╠Ä└ĒŲ„╔Ž┤µį┌Ą─╠žąį╩ŪĖ▀░µ▒Š╠Ä└ĒŲ„╦∙ø](m©”i)ėąĄ─ĪŻ
- Å─▄ø╝■ĮŪČ╚üĒ(l©ói)┐┤Ż║CMSIS╠ß╣®Ą─Ņ^╬─╝■║═╣”─▄║»öĄ(sh©┤)╩ŪČ■▀M(j©¼n)ųŲŽ“╔Ž╝µ╚▌Ą─Ż¼▒╚╚ń─│CM0▄ø╝■App╩╣ė├Ą─╩Ūcore_cm0.hŅ^╬─╝■Ż¼Č°▀@éĆ(g©©)Appę¬į┌CM7╔Ž▀\(y©┤n)ąąĢr(sh©¬)Ż¼▓╗ąĶę¬╩╣ė├core_cm7.hį┘ųžą┬ŠÄūgę╗┤╬Ż©«ö(d©Īng)╚╗╩╣ė├ą┬Ņ^╬─╝■ŠÄūg║¾Ą─Appę▓╩Ūš²│ŻĄ─ĪŻŻ®
Å─MCUā╚(n©©i)║╦ĄĮMCUīŹ(sh©¬)ļHæ¬(y©®ng)ė├╩Ūę╗éĆ(g©©)═Ļš¹Ą─«a(ch©Żn)śI(y©©)µ£Ż¼▀@éĆ(g©©)«a(ch©Żn)śI(y©©)µ£Ęų×ķ╬ÕéĆ(g©©)▓┐ĘųŻ║

ŲõīŹ(sh©¬)Č╝╩Ū▀@śėŻ¼Ū░╚²éĆ(g©©)▓┐ĘųėąąŠŲ¼ÅS╝ę║═╝▄śŗ(g©░u)ā╚(n©©i)║╦╣½╦Šžō(f©┤)ž¤(z©”)ķ_(k©Īi)ąŠŲ¼Ż¼║¾ā╔éĆ(g©©)▓┐Ęųė╔čą░l(f©Ī)╣½╦ŠĖ∙ō■(j©┤)ąŠŲ¼įO(sh©©)ėŗ(j©¼)Ż¼ķ_(k©Īi)░l(f©Ī)ĪŻ
Š═─├ST×ķ└²Ż¼ARM╣½╦Š×ķūŅķ_(k©Īi)╩╝Ą─▓┐ĘųŻ¼STŻ©ęŌĘ©░ļī¦(d©Żo)¾wŻ®×ķąŠŲ¼įO(sh©©)ėŗ(j©¼)┼cųŲįņ╣½╦ŠŻ¼ęįARMā╚(n©©i)║╦×ķ▌d¾wŻ¼═©▀^(gu©░)▀M(j©¼n)ę╗▓ĮĄ─įO(sh©©)ėŗ(j©¼)ķ_(k©Īi)░l(f©Ī)Ż¼×ķARM┼õéõ═Ōć·Ą─ų¦│ųŻ¼×ķīóėŗ(j©¼)╦Ń┐žųŲ─▄┴”æ¬(y©®ng)ė├ĄĮļŖūė«a(ch©Żn)ŲĘųą╠ß╣®ąŠŲ¼Ę■äš(w©┤)
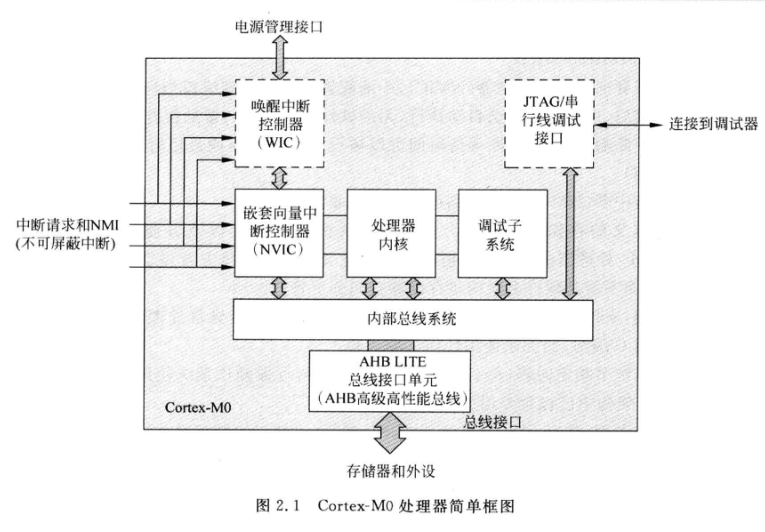
Cortex-M0 ╠Ä└ĒŲ„║å(ji©Żn)Įķ
ARM╣½╦ŠĄ─Cortex-M0æ¬(y©®ng)ė├ė┌Ė„ĘN╬ó┐žųŲŲ„Ż©MCUŻ®ųąŻ¼▓ó┐╔ūīčą░l(f©Ī)╣ż│╠Ĥęį8╬╗Ą─ār(ji©ż)╬╗äō(chu©żng)įņ32╬╗Ą─Ą─ą¦─▄Ż¼▓óīóé„Įy(t©»ng)Ą─8╬╗║═16╬╗Ą─╠Ä└ĒŲ„╔²╝ē(j©¬)ĄĮĖ³Ė▀ą¦ĪóĖ³Ą═╣”║─Ą─32╬╗╠Ä└ĒŲ„ĪŻ
Cortex-M0╩ŪCortex-M╝ęūÕųąĄ─M0ŽĄ┴ąĪŻūŅ┤¾╠ž³c(di©Żn)╩ŪĄ═╣”║─Ą─įO(sh©©)ėŗ(j©¼)ĪŻCortex-M0×ķ32╬╗Īó3╝ē(j©¬)┴„╦«ŠĆRISC╠Ä└ĒŲ„Ż¼Ųõ║╦ą─╚į×ķ±T.ųZę└┬³ĮY(ji©”)śŗ(g©░u)Ż¼╩ŪųĖ┴Ņ║═öĄ(sh©┤)ō■(j©┤)╣▓ŽĒ═¼ę╗┐éŠĆĄ─╝▄śŗ(g©░u)ĪŻū„×ķą┬ę╗┤·Ą─╠Ä└ĒŲ„Ż¼Cortex-M0Ą─įO(sh©©)ėŗ(j©¼)▀M(j©¼n)ąą┴╦įSČÓĄ─Ė─Ė’┼cäō(chu©żng)ą┬Ż¼╚ńŽĄĮy(t©»ng)┤µā”(ch©│)Ų„ĄžųĘė│Ž±(system address map)ĪóĖ─╔Ųą¦┬╩▓óį÷ÅŖ(qi©óng)┤_Č©ąįĄ─ŪČ╠ūŽ“┴┐ųąöÓŽĄĮy(t©»ng)(NVIC)┼c▓╗┐╔Ų┴▒╬ųąöÓ(NMI)Īó╚½ą┬Ą─ė▓╝■│²Õe(cu©░)å╬į¬Ą╚Ą╚Ż¼Č╝ĦĮo┴╦╩╣ė├š▀╚½ą┬Ą─¾w“×(y©żn)║═Ė³▒Ń└¹Īó Ė³ėąą¦┬╩Ą─▓┘ū„ĪŻ
╝╝ąg(sh©┤)╝▄śŗ(g©░u)
CortexM0Ųõ║╦ą─╝▄śŗ(g©░u)×ķARMv6MŻ¼Ųõ▀\(y©┤n)╦Ń─▄┴”┐╔ęį▀_(d©ó)ĄĮ0.9 DMIPS/MHzŻ¼Č°┼cŲõ╦¹Ą─16╬╗┼c8╬╗╠Ä└ĒŲ„ŽÓ▒╚Ż¼ė╔ė┌CortexM0Ą─▀\(y©┤n)╦Ńąį─▄┤¾Ę∙╠ßĖ▀Ż¼╦∙ęįį┌═¼śė╚╬äš(w©┤)Ą─ł╠(zh©¬)ąą╔ŽCortexM0ų╗ąĶ▌^Ą═Ą─▀\(y©┤n)ąą╦┘Č╚Ż¼Č°┤¾Ę∙ĮĄĄ═┴╦š¹¾wĄ─äė(d©░ng)æB(t©żi)╣”║─ĪŻ
Cortex—M0ī┘ė┌ARMv6-M╝▄śŗ(g©░u)Ż¼░³└©1ŅwīŻ(zhu©Īn)×ķŪČ╚ļ╩Įæ¬(y©®ng)ė├Č°įO(sh©©)ėŗ(j©¼)Ą─ARM║╦ĪóŠo±Ņ║ŽĄ─┐╔ŪČ╠ūųąöÓ╬ó┐žųŲŲ„NVICĪó┐╔▀xĄ─åŠąčųąöÓ┐žųŲŲ„WICŻ¼ī”(du©¼)═Ō╠ß╣®┴╦╗∙ė┌AMBAĮY(ji©”)śŗ(g©░u)Ż©Ė▀╝ē(j©¬)╬ó┐žųŲŲ„┐éŠĆ╝▄śŗ(g©░u)Ż®Ą─AHB-lite┐éŠĆ║═╗∙ė┌CoreSight╝╝ąg(sh©┤)Ą─SWD╗“JTAGš{(di©żo)įćĮė┐┌Ż¼╚ńłD╦∙╩ŠĪŻCortex-M0╬ó┐žųŲŲ„Ą─ė▓╝■īŹ(sh©¬)¼F(xi©żn)░³║¼ČÓéĆ(g©©)┐╔┼õų├▀xĒŚ(xi©żng)Ż║ųąöÓöĄ(sh©┤)┴┐ĪóWICĪó╦»├▀─Ż╩Į║═╣Ø(ji©”)─▄┤ļ╩®Īó┤µā”(ch©│)ŽĄĮy(t©»ng)┤¾ąĪČ╦─Ż╩ĮĪóŽĄĮy(t©»ng)Ą╬┤Ģr(sh©¬)ńŖĄ╚Ż¼░ļī¦(d©Żo)¾wÅS╔╠┐╔ęįĖ∙ō■(j©┤)æ¬(y©®ng)ė├ąĶę¬▀xō±║Ž└ĒĄ─┼õų├ĪŻ
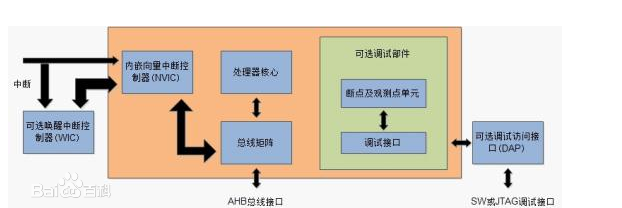

ŽĄĮy(t©»ng)┐éŠĆ╗∙ė┌AHB_LiteĖ▀╝ē(j©¬)Ė▀ąį─▄┐éŠĆģf(xi©”)ūhĪŻ═ŌįO(sh©©)┐éŠĆ╗∙ė┌APBĖ▀╝ē(j©¬)═ŌįO(sh©©)┐éŠĆģf(xi©”)ūhŻ¼═©▀^(gu©░)ę╗éĆ(g©©)▐D(zhu©Żn)ōQś“▀BĮėĄĮAHB╔Ž,▀@ų╗╩ŪCortex-M0ā╚(n©©i)║╦Ą─┤¾Ė┼─Ż╩Į.
╠ž³c(di©Żn)
1Ż®─▄║─ą¦┬╩
CortexM0Ą─▀\(y©┤n)ąąą¦┬╩║▄Ė▀Ż©0.9DMIPS/MHzŻ®Ż¼─▄į┌▌^╔┘Ą─ų▄Ų┌└’═Ļ│╔ę╗ĒŚ(xi©żng)╚╬äš(w©┤)ĪŻ▀@ęŌ╬Čų°CortexM0┐╔ęįį┌┤¾▓┐ĘųĄ─Ģr(sh©¬)ķg└’╠Äė┌ą▌├▀ĀŅæB(t©żi)Ż¼Ž¹║─║▄╔┘Ą──▄┴┐Ż¼Š▀ėą┴╝║├Ą──▄║─ą¦┬╩ĪŻ═¼śė▌^ąĪĄ─▀ē▌ŗķT(m©”n)öĄ(sh©┤)ę▓ĮĄĄ═┴╦┤²ÖC(j©®)ļŖ┴„ĪŻČ°Ė▀ą¦Ą─ųąöÓ┐žųŲŲ„Ż©NVICŻ®ąĶę¬║▄ąĪĄ─ųąöÓķ_(k©Īi)õN(xi©Īo)ĪŻ
2Ż®┤·┤a├▄Č╚
Cortex-M0╗∙ė┌Thumb-2Ą─ųĖ┴Ņ╝»Ż¼▒╚ė├8╬╗╗“š▀16╬╗╝▄śŗ(g©░u)īŹ(sh©¬)¼F(xi©żn)Ą─┤·┤a▀Ćę¬╔┘Ż¼ę“┤╦ė├æ¶┐╔ęį▀xō±Š▀ėą▌^ąĪFlash┐šķgĄ─ąŠŲ¼ĪŻ┐╔ęįĮĄĄ═ŽĄĮy(t©»ng)╣”║─ĪŻ[1]
3Ż® ęūė┌╩╣ė├
Cortex-M0▀mė├ė┌CšZ(y©│)čįŠÄ│╠Ż¼▓óŪę▒╗įSČÓŠÄūgŲ„ų¦│ųĪŻ┐╔ęįė├CšZ(y©│)čįų▒ĮėŠÄ│╠ųąöÓ└²│╠Ż¼Č°¤o(w©▓)ąĶ╩╣ė├ģRŠÄšZ(y©│)čįĪŻ═¼Ģr(sh©¬)Cortex-M0▀Ć▒╗ČÓĘNķ_(k©Īi)░l(f©Ī)╣żŠ▀ų¦│ųĪŻ░³└©║▄ČÓķ_(k©Īi)į┤Ą─ŪČ╚ļ╩Į▓┘ū„ŽĄĮy(t©»ng)═¼śėų¦│ųCortex-M0ĪŻ
ĪĪ
Cortex-M0 ╠Ä└ĒŲ„║å(ji©Żn)Įķ
1. Cortex-M0 ╠Ä└ĒŲ„╗∙ė┌±TųZę└┬³╝▄śŗ(g©░u)Ż©å╬┐éŠĆĮė┐┌Ż®Ż¼╩╣ė├32╬╗Š½║å(ji©Żn)ųĖ┴Ņ╝»Ż©RISCŻ®Ż¼įōųĖ┴Ņ╝»▒╗ĘQ×ķT(m©”n)humbųĖ┴Ņ╝»ĪŻ┼cų«Ū░ŽÓ▒╚Ż¼ą┬Ą─ųĖ┴Ņ╝»į÷╝ė┴╦ÄūŚlARMv6╝▄śŗ(g©░u)Ą─ųĖ┴ŅŻ¼▓óŪę╝ė╚ļ┴╦eThumb-2ųĖ┴Ņ╝»Ą─▓┐ĘųųĖ┴ŅĪŻThumb-2╝╝ąg(sh©┤)öU(ku©░)š╣┴╦ThumbĄ─æ¬(y©®ng)ė├Ż¼į╩įS╦∙ėąĄ─▓┘ū„Č╝┐╔ęįį┌═¼ę╗ĘNCPUĀŅæB(t©żi)Ž┬ł╠(zh©¬)ąąĪŻThumbųĖ┴Ņ╝»╝╚░³└©16╬╗ųĖ┴ŅŻ¼ę▓░³└©32╬╗ųĖ┴ŅĪŻCŠÄūgŲ„╔·│╔Ą─ųĖ┴Ņ┤¾▓┐Ęų╩Ū16╬╗Ą─Ż¼«ö(d©Īng)16╬╗Ą─ųĖ┴Ņ¤o(w©▓)Ę©īŹ(sh©¬)¼F(xi©żn)╦∙ąĶꬥ─▓┘ū„Ģr(sh©¬)Ż¼32╬╗ųĖ┴ŅŠ═Ģ■(hu©¼)░l(f©Ī)ō]ū„ė├ĪŻ▀@śėęįüĒ(l©ói)Ż¼į┌┤·┤a├▄Č╚Ą├ĄĮ╠ß╔²Ą─═¼Ģr(sh©¬)Ż¼▀Ć▒▄├Ō┴╦ā╔╠ūųĖ┴Ņ╝»ų«ķg▀M(j©¼n)ąąŪąōQĦüĒ(l©ói)Ą─ķ_(k©Īi)õN(xi©Īo)
ĪĪĪĪ2. Cortex-M0┐é╣▓ų¦│ų56éĆ(g©©)╗∙▒ŠųĖ┴ŅŻ¼Ųõųą─│ą®ųĖ┴Ņ┐╔─▄Ģ■(hu©¼)ėąČÓĘNą╬╩ĮĪŻŽÓī”(du©¼)ė┌Cortex-M0▌^ąĪĄ─ųĖ┴Ņ╝»Ż¼Ųõ╠Ä└ĒŲ„Ą──▄┴”┐╔▓╗ę╗░ŃŻ¼ę“?y©żn)ķT(m©”n)humb╩ŪĮø(j©®ng)▀^(gu©░)Ė▀Č╚ā×(y©Łu)╗»Ą─ųĖ┴Ņ╝»ĪŻÅ─└ĒšōüĒ(l©ói)šf(shu©Ł)Ż¼ė╔ė┌ūxīæ(xi©¦)┤µā”(ch©│)╩ŪĄ─ųĖ┴Ņ╩ŪŽÓ╗ź¬Ü(d©▓)┴óĄ─Ż¼Č°Ūę╦ŃöĄ(sh©┤)╗“▀ē▌ŗ▓┘ū„Ą─ųĖ┴Ņ╩╣ė├╝─┤µŲ„Ż¼Cortex-M0╠Ä└ĒŲ„┐╔ęį▒╗ÜwĄĮ╝ė▌d-┤µā”(ch©│)Ż©load-storeŻ®ĮY(ji©”)śŗ(g©░u)ųąĪŻ
ĪĪ
ĪĪ 3. ╠Ä└ĒŲ„║╦ą─░³└©Ż║
- ╝─┤µŲ„ĮM ░³║¼16éĆ(g©©)32╬╗╝─┤µŲ„Ż¼Ųõųąėąę╗ą®╠ž╩Ō╝─┤µŲ„
- ╦Ńąg(sh©┤)▀ē▌ŗå╬į¬
- öĄ(sh©┤)ō■(j©┤)┐éŠĆ
- ┐žųŲ▀ē▌ŗ
ĪĪĪĪ┴„╦«ŠĆĖ∙ō■(j©┤)įO(sh©©)ėŗ(j©¼)┐╔Ęų×ķ╚²ĘNĀŅæB(t©żi)Ż║ ╚ĪųĖĪóūg┤aĪół╠(zh©¬)ąąĪŻ
ĪĪĪĪ4. ŪČ╠ūŽ“┴┐ųąöÓ┐žųŲŲ„Ż©NVICŻ®┐╔ęį╠Ä└ĒūŅČÓ32éĆ(g©©)ųąöÓšł(q©½ng)Ū¾║═ę╗éĆ(g©©)▓╗┐╔Ų┴▒╬ųąöÓŻ©NMIŻ®▌ö╚ļĪŻ
ĪĪĪĪ5. NVICąĶę¬▒╚▌^▀@éĆ(g©©)į┌ł╠(zh©¬)ąąųąöÓ║═šł(q©½ng)Ū¾ųąöÓĄ─ā×(y©Łu)Ž╚╝ē(j©¬)Ż¼Ż¼╚╗║¾ūįäė(d©░ng)ł╠(zh©¬)ąąĖ▀ā×(y©Łu)Ž╚╝ē(j©¬)Ą─ųąöÓĪŻ
ĪĪĪĪ6. ╚ń╣¹ę¬╠Ä└Ēę╗éĆ(g©©)ųąöÓŻ¼NVICĢ■(hu©¼)║═╠Ä└ĒŲ„▀M(j©¼n)ąą═©ą┼Ż¼═©ų¬╠Ä└ĒŲ„ł╠(zh©¬)ąąųąöÓ╠Ä└Ē│╠ą“ĪŻ
ĪĪĪĪ7. åŠąčųąöÓ┐žųŲŲ„(WIC)×ķ┐╔▀xĄ─å╬į¬Ż¼į┌Ą═╣”║─æ¬(y©®ng)ė├ųąŻ¼į┌ĻP(gu©Īn)ķ]┴╦╠Ä└ĒŲ„┤¾▓┐Ęų─ŻēK║¾Ż¼╬ó┐žųŲŲ„Ģ■(hu©¼)▀M(j©¼n)╚ļ┤²ÖC(j©®)čb╠ŅŻ¼┤╦Ģr(sh©¬)Ż¼WIC┐╔ęįį┌NVIC║═╠Ä└ĒŲ„╠Äė┌ą▌├▀Ą─ŪķørŽ┬Ż¼ł╠(zh©¬)ąąųąöÓŲ┴▒╬╣”─▄ĪŻ«ö(d©Īng)WICÖz£y(c©©)ĄĮę╗éĆ(g©©)ųąöÓĢr(sh©¬)Ż¼Ģ■(hu©¼)═©ų¬ļŖį┤╣▄└Ē▓┐ĘųĮoŽĄĮy(t©»ng)╔╠ĄĻŻ¼ūīNVIC║═╠Ä└ĒŲ„ā╚(n©©i)║╦ł╠(zh©¬)ąą╩ŻėÓĄ─ųąöÓ╠Ä└ĒĪŻ
ĪĪĪĪ8. ĻP(gu©Īn)ė┌š{(di©żo)įćūėŽĄĮy(t©»ng)Ż¼«ö(d©Īng)š{(di©żo)įć╩┬╝■░l(f©Ī)╔·Ģr(sh©¬)Ż¼╠Ä└ĒŲ„ā╚(n©©i)║╦Ģ■(hu©¼)▒╗ų├ė┌Ģ║═ŻĀŅæB(t©żi)Ż¼▀@╩Ūķ_(k©Īi)░l(f©Ī)╚╦åT┐╔ęįÖz▓ķ«ö(d©Īng)Ū░╠Ä└ĒŲ„Ą─ĀŅæB(t©żi)ĪŻė▓╝■š{(di©żo)įć╣żŠ▀ėąJTAG║═SWDŻ©┤«ąąŠĆš{(di©żo)į毮ĪŻ ![image]()
ARM Cortex-M0 ╠Ä└ĒŲ„Ą─╠žąį
ŽĄĮy(t©»ng)╠žąį
- thumbųĖ┴Ņ╝»Ż¼Š▀ėąĖ▀ą¦║═Ė▀┤·┤a├▄Č╚
- Ė▀ąį─▄Ż¼ūŅĖ▀▀_(d©ó)ĄĮ0.9DMIPS/MHz
- ā╚(n©©i)ų├Ą─ŪČ╠ūŽ“┴┐ųąöÓ┐žųŲŲ„Ż©NVICŻ®Ż¼ųąöÓ┼õų├║═«É│Ż╠Ä└Ē╚▌ęū
- ┤_Č©Ą─ųąöÓĒææ¬(y©®ng)╩┬╝■Ż¼ųąöÓĄ╚┤²╩┬╝■┐╔ęį▒╗įO(sh©©)Č©×ķ╣╠Č©ųĄ╗“ūŅČ╠╩┬╝■Ż©ūŅąĪ16éĆ(g©©)Ģr(sh©¬)ńŖų▄Ų┌Ż®
- ▓╗┐╔Ų┴▒╬ųąöÓŻ©NMIŻ®Ż¼ī”(du©¼)Ė▀┐╔┐┐ąįŽĄĮy(t©»ng)ĘŪ│Żųžę¬
- ā╚(n©©i)ų├Ą─ŽĄĮy(t©»ng)╣Ø(ji©”)┼─Č©Ģr(sh©¬)Ų„Ż©systickŻ®ĪŻ24╬╗Č©Ģr(sh©¬)Ų„Ż¼┐╔▒╗▓┘ū„ŽĄĮy(t©»ng)╩╣ė├Ż¼╗“š▀ė├ū„═©ė├Č©Ģr(sh©¬)Ų„Ż¼╝▄śŗ(g©░u)ųąęčĮø(j©®ng)░³║¼īŻ(zhu©Īn)ė├Ą─«É│ŻŅÉ(l©©i)ą═
- šł(q©½ng)Ū¾╣▄└Ēš{(di©żo)ė├Ż¼Š▀ėąSVC«É│Ż║═PendSV«É│ŻŻ©┐╔ÆņŲĄ─╣▄└ĒĘ■äš(w©┤)Ż®Ż¼ų¦│ųŪČ╚ļ╩ĮosĄ─ČÓĘN▓┘ū„
- ╝▄śŗ(g©░u)Č©┴xĄ─ą▌├▀─Ż╩Į║═▀M(j©¼n)╚ļą▌├▀Ą─ųĖ┴ŅŻ¼ą▌├▀╠žąį─▄┤¾┤¾ĮĄĄ═─▄┴┐Ą─Ž¹║─ĪŻė╔ė┌▀M(j©¼n)╚ļą▌├▀ĀŅæB(t©żi)ąĶę¬╩╣ė├╠žČ©Ą─ųĖ┴ŅŻ¼Č°▓╗╩Ū╩╣ė├╝─┤µŲ„Ż¼╝▄śŗ(g©░u)Č©┴xĄ─ą▌├▀─Ż╩Įę▓╠ßĖ▀┴╦▄ø╝■Ą─┐╔ęŲų▓ąįĪŻ
- «É│Ż╠Ä└Ē┐╔ęį▓Č½@ĄĮŽĄĮy(t©»ng)ųąĄ─ČÓĘNÕe(cu©░)š`ĪŻ
æ¬(y©®ng)ė├╠žąį
- ųąöÓöĄ(sh©┤)┴┐┐╔┼õų├
- ų¦│ų┤¾Č╦╗“ąĪČ╦┤µā”(ch©│)Ų„
- ┐╔▀xō±Ą─åŠąčųąöÓ┐žųŲŲ„Ż©WICŻ®Ż¼╠Ä└ĒŲ„┐╔ęįį┌ą▌├▀ĀŅæB(t©żi)Ž┬Ą¶ļŖęįĮĄĄ═╣”║─Ż¼Č°WIC┐╔ęįį┌ųąöÓ░l(f©Ī)╔·Ģr(sh©¬)åŠąčŽĄĮy(t©»ng)
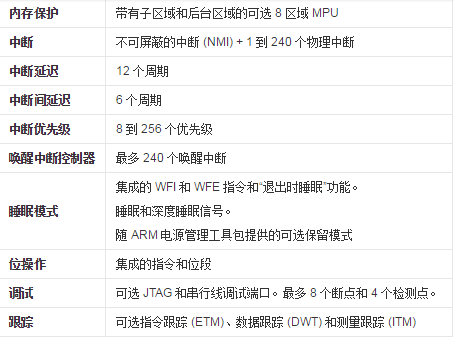
Cortex-M3
Cortex-M3╩Ūę╗éĆ(g©©)32╬╗Ą─║╦Ż¼į┌é„Įy(t©»ng)Ą─å╬Ų¼ÖC(j©®)ŅI(l©½ng)ė“ųąŻ¼ėąę╗ą®▓╗═¼ė┌═©ė├32╬╗CPUæ¬(y©®ng)ė├Ą─ę¬Ū¾ĪŻį┌╣ż┐žŅI(l©½ng)ė“Ż¼ė├æ¶ę¬Ū¾Š▀ėąĖ³┐ņĄ─ųąöÓ╦┘Č╚Ż¼Cortex-M3▓╔ė├┴╦Tail-Chaining
ųąöÓ╝╝ąg(sh©┤)Ż¼═Ļ╚½╗∙ė┌ė▓╝■▀M(j©¼n)ąą
ųąöÓ╠Ä└ĒŻ¼ūŅČÓ┐╔£p╔┘12éĆ(g©©)
Ģr(sh©¬)ńŖų▄Ų┌öĄ(sh©┤)Ż¼į┌īŹ(sh©¬)ļHæ¬(y©®ng)ė├ųą┐╔£p╔┘70%ųąöÓĪŻ
Ė┼╩÷
Cortex-M3╩Ūę╗éĆ(g©©)32╬╗╠Ä└ĒŲ„ā╚(n©©i)║╦ĪŻā╚(n©©i)▓┐Ą─öĄ(sh©┤)ō■(j©┤)┬ĘÅĮ╩Ū32╬╗Ą─Ż¼╝─┤µŲ„╩Ū32╬╗Ą─Ż¼┤µā”(ch©│)Ų„Įė┐┌ę▓╩Ū32╬╗Ą─ĪŻCM3▓╔ė├┴╦╣■ĘĮY(ji©”)śŗ(g©░u)Ż¼ōĒėą¬Ü(d©▓)┴óĄ─ųĖ┴Ņ┐éŠĆ║═öĄ(sh©┤)ō■(j©┤)┐éŠĆŻ¼┐╔ęįūī╚ĪųĖ┼cöĄ(sh©┤)ō■(j©┤)įLå¢(w©©n)▓óąą▓╗ŃŻĪŻ▀@śėę╗üĒ(l©ói)öĄ(sh©┤)ō■(j©┤)įLå¢(w©©n)▓╗į┘š╝ė├ųĖ┴Ņ┐éŠĆŻ¼Å─Č°╠ß╔²┴╦ąį─▄ĪŻ×ķīŹ(sh©¬)¼F(xi©żn)▀@éĆ(g©©)╠žąįŻ¼CM3ā╚(n©©i)▓┐║¼ėą║├ÄūŚl┐éŠĆĮė┐┌Ż¼├┐ŚlČ╝×ķūį╝║Ą─æ¬(y©®ng)ė├ł÷(ch©Żng)║Žā×(y©Łu)╗»▀^(gu©░)Ż¼▓óŪę╦³éā┐╔ęį▓óąą╣żū„ĪŻĄ½╩Ū┴Ēę╗ĘĮ├µŻ¼ųĖ┴Ņ┐éŠĆ║═öĄ(sh©┤)ō■(j©┤)┐éŠĆ╣▓ŽĒ═¼ę╗éĆ(g©©)┤µā”(ch©│)Ų„┐šķgŻ©ę╗éĆ(g©©)Įy(t©»ng)ę╗Ą─┤µā”(ch©│)Ų„ŽĄĮy(t©»ng)Ż®ĪŻōQŠõįÆšf(shu©Ł)Ż¼▓╗╩Ūę“?y©żn)ķėąā╔Śl┐éŠĆŻ¼┐╔īżųĘ┐šķgŠ═ūā│╔8GB┴╦ĪŻ
▒╚▌^Å═(f©┤)ļsĄ─æ¬(y©®ng)ė├┐╔─▄ąĶę¬Ė³ČÓĄ─┤µā”(ch©│)ŽĄĮy(t©»ng)╣”─▄Ż¼×ķ┤╦CM3╠ß╣®ę╗éĆ(g©©)┐╔▀xĄ─MPUŻ¼Č°Ūęį┌ąĶꬥ─ŪķørŽ┬ę▓┐╔ęį╩╣ė├═Ō▓┐Ą─cacheĪŻ┴Ē═Ōį┌CM3ųąŻ¼BothąĪČ╦─Ż╩Į║═┤¾Č╦─Ż╩ĮČ╝╩Ūų¦│ųĄ─ĪŻ
CM3ā╚(n©©i)▓┐▀ĆĖĮ┘ø(z©©ng)┴╦║├ČÓš{(di©żo)įćĮM╝■Ż¼ė├ė┌į┌ė▓╝■╦«ŲĮ╔Žų¦│ųš{(di©żo)įć▓┘ū„Ż¼╚ńųĖ┴ŅöÓ³c(di©Żn)Ż¼öĄ(sh©┤)ō■(j©┤)ė^▓ņ³c(di©Żn)Ą╚ĪŻ┴Ē═ŌŻ¼×ķų¦│ųĖ³Ė▀╝ē(j©¬)Ą─š{(di©żo)įćŻ¼▀ĆėąŲõ╦³┐╔▀xĮM╝■Ż¼░³└©ųĖ┴ŅĖ·█Ö║═ČÓĘNŅÉ(l©©i)ą═Ą─š{(di©żo)įćĮė┐┌ĪŻ
ā╚(n©©i)║╦╝▄śŗ(g©░u)
ARMCortex-M3▓╔ė├╣■ĘĮY(ji©”)śŗ(g©░u)Ż¼▓ó▀xō±┴╦▀m║Žė┌╬ó┐žųŲŲ„æ¬(y©®ng)ė├Ą─╚²╝ē(j©¬)┴„╦«ŠĆŻ¼Ą½į÷╝ė┴╦Ęųų¦ŅA(y©┤)£y(c©©)╣”─▄ĪŻ
¼F(xi©żn)┤·╠Ä└ĒŲ„┤¾ČÓ▓╔ė├ųĖ┴ŅŅA(y©┤)╚Ī║═┴„╦«ŠĆ╝╝ąg(sh©┤)Ż¼ęį╠ßĖ▀╠Ä└ĒŲ„Ą─ųĖ┴Ņł╠(zh©¬)ąą╦┘Č╚ĪŻ┴„╦«ŠĆ╠Ä└ĒŲ„į┌š²│Żł╠(zh©¬)ąąųĖ┴ŅĢr(sh©¬)Ż¼╚ń╣¹┼÷ĄĮĘųų¦Ż©╠°▐D(zhu©Żn)Ż®ųĖ┴ŅŻ¼ė╔ė┌ųĖ┴Ņł╠(zh©¬)ąąĄ─Ēśą“┐╔─▄Ģ■(hu©¼)░l(f©Ī)╔·ūā╗»Ż¼ųĖ┴ŅŅA(y©┤)╚ĪĻĀ(du©¼)┴ą║═┴„╦«ŠĆųąĄ─▓┐ĘųųĖ┴ŅŠ═┐╔─▄ū„ÅUŻ¼Č°ąĶę¬Å─ą┬Ą─ĄžųĘųžą┬╚ĪųĖĪół╠(zh©¬)ąąŻ¼▀@śėŠ═Ģ■(hu©¼)╩╣┴„╦«ŠĆ“öÓ┴„”Ż¼╠Ä└ĒŲ„ąį─▄ę“┤╦Č°╩▄ĄĮė░ĒæĪŻ╠žäe╩Ū¼F(xi©żn)┤·CšZ(y©│)čį│╠ą“Ż¼Įø(j©®ng)ŠÄūgŲ„ā×(y©Łu)╗»╔·│╔Ą──┐ś╦(bi©Īo)┤·┤aųąŻ¼Ęųų¦ųĖ┴Ņ╦∙š╝Ą─▒╚└²┐╔▀_(d©ó)10-20%Ż¼ī”(du©¼)┴„╦«ŠĆ╠Ä└ĒŲ„Ą─ė░ĒæĢ■(hu©¼)Ą─Ė³┤¾ĪŻ×ķ┤╦Ż¼¼F(xi©żn)┤·Ė▀ąį─▄┴„╦«ŠĆ╠Ä└ĒŲ„ųąę╗░ŃČ╝╝ė╚ļ┴╦Ęųų¦ŅA(y©┤)£y(c©©)▓┐╝■Ż¼Š═╩Ūį┌╠Ä└ĒŲ„Å─┤µā”(ch©│)Ų„ŅA(y©┤)╚ĪųĖ┴ŅĢr(sh©¬)Ż¼«ö(d©Īng)ė÷ĄĮĘųų¦Ż©╠°▐D(zhu©Żn)Ż®ųĖ┴ŅĢr(sh©¬)Ż¼─▄ūįäė(d©░ng)ŅA(y©┤)£y(c©©)╠°▐D(zhu©Żn)╩ŪʱĢ■(hu©¼)░l(f©Ī)╔·Ż¼į┘?g©░u)─ŅA(y©┤)£y(c©©)Ą─ĘĮŽ“▀M(j©¼n)ąą╚ĪųĖŻ¼Å─Č°╠ß╣®Įo┴„╦«ŠĆ▀B└m(x©┤)Ą─ųĖ┴Ņ┴„Ż¼┴„╦«ŠĆŠ═┐╔ęį▓╗öÓĄžł╠(zh©¬)ąąėąą¦ųĖ┴ŅŻ¼▒ŻūC┴╦Ųõąį─▄Ą─░l(f©Ī)ō]ĪŻ
ARMCortex-M3ā╚(n©©i)║╦Ą─ŅA(y©┤)╚Ī▓┐╝■Š▀ėąĘųų¦ŅA(y©┤)£y(c©©)╣”─▄Ż¼┐╔ęįŅA(y©┤)╚ĪĘųų¦─┐ś╦(bi©Īo)ĄžųĘĄ─ųĖ┴ŅŻ¼╩╣Ęųų¦čė▀t£p╔┘ĄĮę╗éĆ(g©©)Ģr(sh©¬)ńŖų▄Ų┌ĪŻ
ßśī”(du©¼)śI(y©©)Įńī”(du©¼)ARM╠Ä└ĒŲ„ųąöÓĒææ¬(y©®ng)Ą─å¢(w©©n)Ņ}Ż¼Cortex-M3╩ū┤╬į┌ā╚(n©©i)║╦╔Ž╝»│╔┴╦ŪČ╠ūŽ“┴┐ųąöÓ┐žųŲŲ„Ż©NVICŻ®ĪŻCortex-M3Ą─ųąöÓčė▀tų╗ėą12éĆ(g©©)Ģr(sh©¬)ńŖų▄Ų┌(ARM7ąĶę¬24-42éĆ(g©©)ų▄Ų┌)Ż╗Cortex-M3▀Ć╩╣ė├╬▓µ£╝╝ąg(sh©┤)Ż¼╩╣Ą├▒│┐┐▒│Ż©back-to-backŻ®ųąöÓĄ─Ēææ¬(y©®ng)ų╗ąĶę¬6éĆ(g©©)Ģr(sh©¬)ńŖų▄Ų┌(ARM7ąĶę¬┤¾ė┌30éĆ(g©©)ų▄Ų┌)ĪŻCortex-M3▓╔ė├┴╦╗∙ė┌ŚŻĄ─«É│Ż─Ż╩ĮŻ¼╩╣Ą├ąŠŲ¼│§╩╝╗»Ą─ĘŌčbĖ³×ķ║å(ji©Żn)å╬ĪŻ
Cortex-M3╝ė╚ļ┴╦ŅÉ(l©©i)╦Ųė┌8╬╗╠Ä└ĒŲ„Ą─ā╚(n©©i)║╦Ą═╣”║──Ż╩ĮŻ¼ų¦│ų3ĘN╣”║─╣▄└Ē─Ż╩ĮŻ║═©▀^(gu©░)ę╗ŚlųĖ┴Ņ┴ó╝┤╦»├▀Ż╗«É│Ż/ųąöÓ═╦│÷Ģr(sh©¬)╦»├▀Ż╗╔ŅČ╚╦»├▀ĪŻ╩╣š¹éĆ(g©©)ąŠŲ¼Ą─╣”║─┐žųŲĖ³×ķėąą¦ĪŻ
╠ž³c(di©Żn)
Ė▀ąį─▄
? įSČÓųĖ┴ŅČ╝╩Ūå╬ų▄Ų┌Ą─——░³└©│╦Ę©ŽÓĻP(gu©Īn)ųĖ┴ŅĪŻ▓óŪęÅ─š¹¾wąį─▄╔ŽŻ¼Cortex-M3▒╚Ą├▀^(gu©░)Į^┤¾ČÓöĄ(sh©┤)Ųõ╦³Ą─╝▄śŗ(g©░u)ĪŻ
? ųĖ┴Ņ┐éŠĆ║═öĄ(sh©┤)ō■(j©┤)┐éŠĆ▒╗Ęųķ_(k©Īi)Ż¼╚ĪųĄ║═įLā╚(n©©i)┐╔ęį▓óąą▓╗ŃŻ
? Thumb-2Ą─ĄĮüĒ(l©ói)Ėµäe┴╦ĀŅæB(t©żi)ŪąōQĄ─┼f╩└┤·Ż¼į┘ę▓▓╗ąĶę¬╗©Ģr(sh©¬)ķgüĒ(l©ói)ŪąōQė┌32╬╗ARMĀŅæB(t©żi)║═16╬╗ThumbĀŅæB(t©żi)ų«ķg┴╦ĪŻ▀@║å(ji©Żn)╗»┴╦▄ø╝■ķ_(k©Īi)░l(f©Ī)║═┤·┤aŠSūo(h©┤)Ż¼╩╣«a(ch©Żn)ŲĘ├µ╩ąĖ³┐ņĪŻ
? Thumb-2ųĖ┴Ņ╝»×ķŠÄ│╠ĦüĒ(l©ói)┴╦Ė³ČÓĄ─ņ`╗ŅąįĪŻįSČÓöĄ(sh©┤)ō■(j©┤)▓┘ū„¼F(xi©żn)į┌─▄ė├Ė³Č╠Ą─┤·┤aĖŃČ©Ż¼▀@ęŌ╬Čų°Cortex-M3Ą─┤·┤a├▄Č╚Ė³Ė▀Ż¼ę▓Š═ī”(du©¼)┤µā”(ch©│)Ų„Ą─ąĶŪ¾Ė³╔┘ĪŻ
? ╚ĪųĖČ╝░┤32╬╗╠Ä└ĒĪŻ═¼ę╗ų▄Ų┌ūŅČÓ┐╔ęį╚Ī│÷ā╔ŚlųĖ┴ŅŻ¼┴¶Ž┬┴╦Ė³ČÓĄ─ĦīÆĮoöĄ(sh©┤)ō■(j©┤)é„▌öĪŻ
? Cortex-M3Ą─įO(sh©©)ėŗ(j©¼)į╩įSå╬Ų¼ÖC(j©®)Ė▀Ņl▀\(y©┤n)ąąŻ©¼F(xi©żn)┤·░ļī¦(d©Żo)¾wųŲįņ╝╝ąg(sh©┤)─▄▒ŻūC100MHzęį╔ŽĄ─╦┘Č╚Ż®ĪŻ╝┤╩╣į┌ŽÓ═¼Ą─╦┘Č╚Ž┬▀\(y©┤n)ąąŻ¼CM3Ą─├┐ųĖ┴Ņų▄Ų┌öĄ(sh©┤)(CPI)ę▓Ė³Ą═Ż¼ė┌╩Ū═¼śėĄ─MHzŽ┬┐╔ęįū÷Ė³ČÓĄ─╣żū„Ż╗┴Ēę╗ĘĮ├µŻ¼ę▓╩╣═¼ę╗éĆ(g©©)æ¬(y©®ng)ė├į┌CM3╔ŽąĶę¬Ė³Ą═Ą─ų„ŅlĪŻ
Ž╚▀M(j©¼n)Ą─ųąöÓ╠Ä└Ē╣”─▄
? ā╚(n©©i)Į©Ą─ŪČ╠ūŽ“┴┐ųąöÓ┐žųŲŲ„ų¦│ųČÓ▀_(d©ó)240Śl═Ō▓┐ųąöÓ▌ö╚ļĪŻŽ“┴┐╗»Ą─ųąöÓ╣”─▄äĪ┴꥞┐sČ╠┴╦ųąöÓčė▀tŻ¼ę“?y©żn)ķ▓╗į┘ąĶę¬▄ø╝■╚ź┼ąöÓųąöÓį┤ĪŻųąöÓĄ─ŪČ╠ūę▓╩Ūį┌ė▓╝■╦«ŲĮ╔Žī?sh©¬)¼F(xi©żn)Ą─Ż¼▓╗ąĶę¬▄ø╝■┤·┤aüĒ(l©ói)īŹ(sh©¬)¼F(xi©żn)ĪŻ
? Cortex-M3į┌▀M(j©¼n)╚ļ«É│ŻĘ■äš(w©┤)└²│╠Ģr(sh©¬)Ż¼ūįäė(d©░ng)ē║ŚŻ┴╦R0-R3, R12, LR, PSR║═PCŻ¼▓óŪęį┌ĘĄ╗žĢr(sh©¬)ūįäė(d©░ng)ÅŚ│÷╦³éāŻ¼▀@ČÓŪÕ╦¼ŻĪ╝╚╝ė╦┘┴╦ųąöÓĄ─Ēææ¬(y©®ng)Ż¼ę▓į┘▓╗ąĶę¬ģRŠÄšZ(y©│)čį┤·┤a┴╦ĪŻ
? NVICų¦│ųī”(du©¼)├┐ę╗┬ĘųąöÓįO(sh©©)ų├▓╗═¼Ą─ā×(y©Łu)Ž╚╝ē(j©¬)Ż¼╩╣Ą├ųąöÓ╣▄└ĒśOĖ╗ÅŚąįĪŻūŅ┤ųŠĆŚlĄ─īŹ(sh©¬)¼F(xi©żn)ę▓ų┴╔┘ę¬ų¦│ų8╝ē(j©¬)ā×(y©Łu)Ž╚╝ē(j©¬)Ż¼Č°Ūę▀Ć─▄äė(d©░ng)æB(t©żi)Ąž▒╗ą▐Ė─ĪŻ
? ā×(y©Łu)╗»ųąöÓĒææ¬(y©®ng)▀Ćėąā╔šąŻ¼╦³éāĘųäe╩Ū“ę¦╬▓ųąöÓÖC(j©®)ųŲ”║═“═ĒĄĮųąöÓÖC(j©®)ųŲ”ĪŻ
? ėąą®ąĶę¬▌^ČÓų▄Ų┌▓┼─▄ł╠(zh©¬)ąą═ĻĄ─ųĖ┴ŅŻ¼╩Ū┐╔ęį▒╗ųąöÓŻŁ└^└m(x©┤)Ą─——Š═║├▒╚╦³éā╩Ūę╗┤«ųĖ┴Ņę╗śėĪŻ▀@ą®ųĖ┴Ņ░³└©╝ė▌dČÓéĆ(g©©)╝─┤µŲ„Ż©LDMŻ®Ż¼┤µā”(ch©│)ČÓéĆ(g©©)╝─┤µŲ„Ż©STMŻ®Ż¼ČÓéĆ(g©©)╝─┤µŲ„ģó┼cĄ─PUSHŻ¼ęį╝░ČÓéĆ(g©©)╝─┤µŲ„ģó┼cĄ─POPĪŻ
? │²ĘŪŽĄĮy(t©»ng)▒╗ÅžĄūĄžµiČ©Ż¼NMIŻ©▓╗┐╔Ų┴▒╬ųąöÓŻ®Ģ■(hu©¼)į┌╩šĄĮšł(q©½ng)Ū¾Ą─Ą┌ę╗Ģr(sh©¬)ķgėĶęįĒææ¬(y©®ng)ĪŻī”(du©¼)ė┌║▄ČÓ░▓╚½-ĻP(gu©Īn)µI(safety-critical)Ą─æ¬(y©®ng)ė├Ż¼NMIČ╝╩Ū▒ž▓╗▓╗┐╔╔┘Ą─Ż©╚ń╗»īW(xu©”)Ę┤æ¬(y©®ng)╝┤īó╩¦┐žĢr(sh©¬)Ą─Šo╝▒═ŻÖC(j©®)Ż®ĪŻ
Ą═╣”║─
? Cortex-M3ąĶꬥ─▀ē▌ŗķT(m©”n)öĄ(sh©┤)╔┘Ż¼╦∙ęįŽ╚╠ņŠ═▀m║ŽĄ═╣”║─ę¬Ū¾Ą─æ¬(y©®ng)ė├Ż©╣”┬╩Ą═ė┌0.19mW/MHzŻ®į┌ā╚(n©©i)║╦╦«ŲĮ╔Žų¦│ų╣Ø(ji©”)─▄─Ż╩ĮŻ©SLEEPING║═SLEEPDEEP╬╗Ż®ĪŻ═©▀^(gu©░)╩╣ė├“Ą╚┤²ųąöÓųĖ┴ŅŻ©WFIŻ®”║═“Ą╚┤²╩┬╝■ųĖ┴ŅŻ©WFEŻ®”Ż¼ā╚(n©©i)║╦┐╔ęį▀M(j©¼n)╚ļ╦»├▀─Ż╩ĮŻ¼▓óŪęęį▓╗═¼Ą─ĘĮ╩ĮåŠąčĪŻ┴Ē═ŌŻ¼─ŻēKĄ─Ģr(sh©¬)ńŖ╩Ū▒M┐╔─▄ĄžĘųķ_(k©Īi)╣®æ¬(y©®ng)Ą─Ż¼╦∙ęįį┌╦»├▀Ģr(sh©¬)┐╔ęį░čCM3Ą─┤¾ČÓöĄ(sh©┤)“╣┘─▄łF(tu©ón)”Įo═ŻĄ¶ĪŻ
? CM3Ą─įO(sh©©)ėŗ(j©¼)╩Ū╚½ņoæB(t©żi)Ą─Īó═¼▓ĮĄ─Īó┐╔ŠC║ŽĄ─ĪŻ╚╬║╬Ą═╣”║─Ą─╗“╩Ūś╦(bi©Īo)£╩(zh©│n)Ą─░ļī¦(d©Żo)¾w╣ż╦ćŠ∙┐╔Ę┼ą─’ŗė├ĪŻ
ŽĄĮy(t©»ng)╠žąį
? ŽĄĮy(t©»ng)ų¦│ų“╬╗īżųĘĦ”▓┘ū„Ż©8051╬╗īżųĘÖC(j©®)ųŲĄ─“═■┴”┤¾Ę∙╝ėÅŖ(qi©óng)░µ”Ż®Ż¼ūų╣Ø(ji©”)▓╗ūāĄ─┤¾Č╦─Ż╩ĮŻ¼▓óŪęų¦│ųĘŪī”(du©¼)²RĄ─öĄ(sh©┤)ō■(j©┤)įLå¢(w©©n)ĪŻ
? ōĒėąŽ╚▀M(j©¼n)Ą─fault╠Ä└ĒÖC(j©®)ųŲŻ¼ų¦│ųČÓĘNŅÉ(l©©i)ą═Ą─«É│Ż║═faultsŻ¼╩╣╣╩šŽį\öÓĖ³╚▌ęūĪŻ
? ═©▀^(gu©░)ę²╚ļbankedČ茯ųĖßśÖC(j©®)ųŲŻ¼░莥Įy(t©»ng)│╠ą“╩╣ė├Ą─Č茯║═ė├æ¶│╠ą“╩╣ė├Ą─Č茯äØŪÕĮńŠĆĪŻ╚ń╣¹į┘┼õ╔Ž┐╔▀xĄ─MPUŻ¼╠Ä└ĒŲ„Š═─▄ÅžĄūØMūŃī”(du©¼)▄ø╝■ĮĪēčąį║═┐╔┐┐ąįėąć└(y©ón)Ė±ę¬Ū¾Ą─æ¬(y©®ng)ė├ĪŻ
š{(di©żo)įćų¦│ų
? į┌ų¦│ųé„Įy(t©»ng)Ą─JTAG╗∙ĄA(ch©│)╔ŽŻ¼▀Ćų¦│ųĖ³ą┬Ė³║├Ą─┤«ąąŠĆš{(di©żo)įćĮė┐┌ĪŻ
? ╗∙ė┌CoreSightš{(di©żo)įćĮŌøQĘĮ░ĖŻ¼╩╣Ą├╠Ä└ĒŲ„──┼┬╩Ūį┌▀\(y©┤n)ąąĢr(sh©¬)Ż¼ę▓─▄įLå¢(w©©n)╠Ä└ĒŲ„ĀŅæB(t©żi)║═┤µā”(ch©│)Ų„ā╚(n©©i)╚▌ĪŻ
? ā╚(n©©i)Į©┴╦ī”(du©¼)ČÓ▀_(d©ó)6éĆ(g©©)öÓ³c(di©Żn)║═4éĆ(g©©)öĄ(sh©┤)ō■(j©┤)ė^▓ņ³c(di©Żn)Ą─ų¦│ųĪŻ
? ┐╔ęį▀x┼õę╗éĆ(g©©)ETMŻ¼ė├ė┌ųĖ┴ŅĖ·█ÖĪŻöĄ(sh©┤)ō■(j©┤)Ą─Ė·█Ö┐╔ęį╩╣ė├DWT
? į┌š{(di©żo)įćĘĮ├µ▀Ć╝ė╚ļ┴╦ęįŽ┬Ą─ą┬╠žąįŻ¼░³└©faultĀŅæB(t©żi)╝─┤µŲ„Ż¼ą┬Ą─fault«É│ŻŻ¼ęį╝░ķW┤µą▐ča(b©│) Ż©patchŻ®▓┘ū„Ż¼╩╣Ą├š{(di©żo)įć┤¾Ę∙║å(ji©Żn)╗»ĪŻ
? ┐╔▀xITM─ŻēKŻ¼£y(c©©)įć┤·┤a┐╔ęį═©▀^(gu©░)╦³▌ö│÷š{(di©żo)įćą┼ŽóŻ¼Č°Ūę“┴Ó░³╝┤┐╔╚ļūĪ”░ŃĄžĘĮ▒Ń╩╣ė├ĪŻ
ŠÄ│╠─Ż╩Į
CortexŻŁM3╠Ä└ĒŲ„▓╔ė├ARMv7-M╝▄śŗ(g©░u)Ż¼╦³░³└©╦∙ėąĄ─16╬╗Thumb
ųĖ┴Ņ╝»║═╗∙▒ŠĄ─32╬╗Thumb-2
ųĖ┴Ņ╝»╝▄śŗ(g©░u)Ż¼Cortex-M3╠Ä└ĒŲ„▓╗─▄ł╠(zh©¬)ąąARMųĖ┴Ņ╝»ĪŻ
Thumb-2į┌Thumb
ųĖ┴Ņ╝»╝▄śŗ(g©░u)Ż©ISAŻ®╔Ž▀M(j©¼n)ąą┴╦┤¾┴┐Ą─Ė─▀M(j©¼n)Ż¼╦³┼cThumbŽÓ▒╚Ż¼Š▀ėąĖ³Ė▀Ą─┤·┤a├▄Č╚▓ó╠ß╣®16/32╬╗ųĖ┴ŅĄ─Ė³Ė▀ąį─▄ĪŻ
ĻP(gu©Īn)ė┌╣żū„─Ż╩Į
Cortex-M3╠Ä└ĒŲ„ų¦│ų2ĘN╣żū„─Ż╩ĮŻ║ŠĆ│╠─Ż╩Į║═╠Ä└Ē─Ż╩ĮĪŻį┌Å═(f©┤)╬╗Ģr(sh©¬)╠Ä└ĒŲ„▀M(j©¼n)╚ļ“ŠĆ│╠─Ż╩Į”Ż¼«É│ŻĘĄ╗žĢr(sh©¬)ę▓Ģ■(hu©¼)▀M(j©¼n)╚ļįō─Ż╩ĮŻ¼╠žÖÓ(qu©ón)║═ė├æ¶Ż©ĘŪ╠žÖÓ(qu©ón)Ż®─Ż╩Į┤·┤a─▄ē“į┌“ŠĆ│╠─Ż╩Į”Ž┬▀\(y©┤n)ąąĪŻ
│÷¼F(xi©żn)«É│Ż─Ż╩ĮĢr(sh©¬)╠Ä└ĒŲ„▀M(j©¼n)╚ļ“╠Ä└Ē─Ż╩Į”Ż¼į┌╠Ä└Ē─Ż╩ĮŽ┬Ż¼╦∙ėą┤·┤aČ╝╩Ū╠žÖÓ(qu©ón)įLå¢(w©©n)Ą─ĪŻ
ĻP(gu©Īn)ė┌╣żū„ĀŅæB(t©żi)
Cortex-M3╠Ä└ĒŲ„ėą2ĘN╣żū„ĀŅæB(t©żi)ĪŻ
ThumbĀŅæB(t©żi)Ż║▀@╩Ū16╬╗║═32╬╗“
░ļūųī”(du©¼)²R”Ą─Thumb║═Thumb-2ųĖ┴ŅĄ─ł╠(zh©¬)ąąĀŅæB(t©żi)ĪŻ
š{(di©żo)įćĀŅæB(t©żi)Ż║╠Ä└ĒŲ„═Żų╣▓ó▀M(j©¼n)ąąš{(di©żo)įćŻ¼▀M(j©¼n)╚ļįōĀŅæB(t©żi)ĪŻ
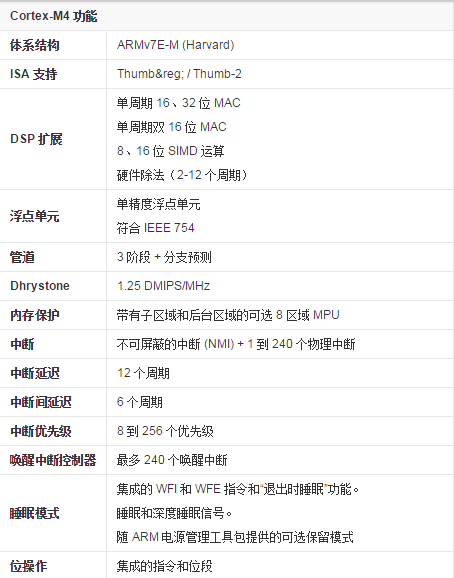
Cortex-M4
╗∙▒Š║å(ji©Żn)Įķ
ARMCortex™-M4╠Ä└ĒŲ„╩Ūė╔ARMīŻ(zhu©Īn)ķT(m©”n)ķ_(k©Īi)░l(f©Ī)Ą─ūŅą┬ŪČ╚ļ╩Į╠Ä└ĒŲ„Ż¼į┌M3Ą─╗∙ĄA(ch©│)╔ŽÅŖ(qi©óng)╗»┴╦▀\(y©┤n)╦Ń─▄┴”Ż¼ą┬╝ė┴╦ĖĪ³c(di©Żn)ĪóDSPĪó▓óąąėŗ(j©¼)╦ŃĄ╚Ż¼ė├ęįØMūŃąĶę¬ėąą¦Ūęęūė┌╩╣ė├Ą─┐žųŲ║═ą┼╠¢(h©żo)╠Ä└Ē╣”─▄╗ņ║ŽĄ─öĄ(sh©┤)ūųą┼╠¢(h©żo)┐žųŲ╩ął÷(ch©Żng)ĪŻŲõĖ▀ą¦Ą─ą┼╠¢(h©żo)╠Ä└Ē╣”─▄┼cCortex-M╠Ä└ĒŲ„ŽĄ┴ąĄ─Ą═╣”║─ĪóĄ═│╔▒Š║═ęūė┌╩╣ė├Ą─ā×(y©Łu)³c(di©Żn)Ą─ĮM║ŽŻ¼ų╝į┌ØMūŃīŻ(zhu©Īn)ķT(m©”n)├µŽ“ļŖäė(d©░ng)ÖC(j©®)┐žųŲĪóŲ¹▄ć(ch©ź)ĪóļŖį┤╣▄└ĒĪóŪČ╚ļ╩Įę¶Ņl║═╣żśI(y©©)ūįäė(d©░ng)╗»╩ął÷(ch©Żng)Ą─ą┬┼dŅÉ(l©©i)äeĄ─ņ`╗ŅĮŌøQĘĮ░ĖĪŻ
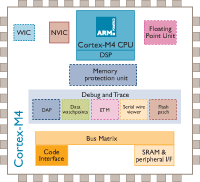
╠žąį
ARMCortex™-M4╠Ä└ĒŲ„ā╚(n©©i)║╦╩Ūį┌Cortex-M3ā╚(n©©i)║╦╗∙ĄA(ch©│)╔Ž░l(f©Ī)š╣ŲüĒ(l©ói)Ą─Ż¼Ųõąį─▄▒╚Cortex-M3╠ßĖ▀┴╦20%ĪŻą┬į÷╝ė┴╦ĖĪ³c(di©Żn)ĪóDSPĪó▓óąąėŗ(j©¼)╦ŃĄ╚ĪŻė├ęįØMūŃąĶę¬ėąą¦Ūęęūė┌╩╣ė├Ą─┐žųŲ║═ą┼╠¢(h©żo)╠Ä└Ē╣”─▄╗ņ║ŽĄ─öĄ(sh©┤)ūųą┼╠¢(h©żo)┐žųŲ╩ął÷(ch©Żng)ĪŻŲõĖ▀ą¦Ą─ą┼╠¢(h©żo)╠Ä└Ē╣”─▄┼cCortex-M╠Ä└ĒŲ„ŽĄ┴ąĄ─Ą═╣”║─ĪóĄ═│╔▒Š║═ęūė┌╩╣ė├Ą─ā×(y©Łu)³c(di©Żn)ŽÓĮY(ji©”)║ŽĪŻ
Cortex-M4╠ß╣®┴╦¤o(w©▓)┐╔▒╚öMĄ─╣”─▄Ż¼īó32╬╗┐žųŲ┼cŅI(l©½ng)Ž╚Ą─öĄ(sh©┤)ūųą┼╠¢(h©żo)╠Ä└Ē╝╝ąg(sh©┤)╝»│╔üĒ(l©ói)ØMūŃąĶę¬║▄Ė▀─▄ą¦╝ē(j©¬)äeĄ─╩ął÷(ch©Żng)ĪŻ
Cortex-M4╠Ä└ĒŲ„▓╔ė├ę╗éĆ(g©©)öU(ku©░)š╣Ą─å╬Ģr(sh©¬)ńŖų▄Ų┌│╦Ę©└█╝ėŻ©MACŻ®å╬į¬Īóā×(y©Łu)╗»Ą─å╬ųĖ┴ŅČÓöĄ(sh©┤)ō■(j©┤)Ż©SIMDŻ®ųĖ┴ŅĪó’¢║═▀\(y©┤n)╦ŃųĖ┴Ņ║═ę╗éĆ(g©©)┐╔▀xĄ─å╬Š½Č╚ĖĪ³c(di©Żn)å╬į¬Ż©FPU)ĪŻ▀@ą®╣”─▄ęį▒Ē¼F(xi©żn)
ARMCortex-MŽĄ┴ą╠Ä└ĒŲ„╠žš„Ą─äō(chu©żng)ą┬╝╝ąg(sh©┤)×ķ╗∙ĄA(ch©│)ĪŻ░³└©
·RISC╠Ä└ĒŲ„ā╚(n©©i)║╦Ż¼Ė▀ąį─▄32╬╗CPUĪóŠ▀ėą┤_Č©ąįĄ─▀\(y©┤n)╦ŃĪóĄ═čė▀t3ļAČ╬╣▄Ą└Ż¼┐╔▀_(d©ó)1.25DMIPS/MHzŻ╗
·Thumb-2ųĖ┴Ņ╝»Ż¼16/32╬╗ųĖ┴ŅĄ─ūŅ╝č╗ņ║ŽĪóąĪė┌8╬╗įO(sh©©)éõ3▒ČĄ─┤·┤a┤¾ąĪĪóī”(du©¼)ąį─▄ø](m©”i)ėąžō(f©┤)├µė░ĒæŻ¼╠ß╣®ūŅ╝čĄ─┤·┤a├▄Č╚Ż╗
·Ą═╣”║──Ż╩ĮŻ¼╝»│╔Ą─╦»├▀ĀŅæB(t©żi)ų¦│ųĪóČÓļŖį┤ė“Īó╗∙ė┌╝▄śŗ(g©░u)Ą─▄ø╝■┐žųŲŻ╗
·ŪČ╠ū╩Ė┴┐ųąöÓ┐žųŲŲ„Ż©NVICŻ®Ż¼Ą═čė▀tĪóĄ═ČČäė(d©░ng)ųąöÓĒææ¬(y©®ng)Īó▓╗ąĶę¬ģRŠÄŠÄ│╠Īóęį╝āCšZ(y©│)čįŠÄīæ(xi©¦)Ą─ųąöÓĘ■äš(w©┤)└²│╠Ż¼─▄═Ļ│╔│÷╔½Ą─ųąöÓ╠Ä└ĒŻ╗
·╣żŠ▀║═RTOSų¦│ųŻ¼ÅVĘ║Ą─Ą┌╚²ĘĮ╣żŠ▀ų¦│ųĪóCortex╬ó┐žųŲŲ„▄ø╝■Įė┐┌ś╦(bi©Īo)£╩(zh©│n)Ż©CMSISŻ®ĪóūŅ┤¾Ž▐Č╚Ąžį÷╝ė▄ø╝■│╔╣¹ųžė├;
·CoreSightš{(di©żo)įć║═Ė·█ÖŻ¼JTAG╗“2ßś┤«ąąŠĆš{(di©żo)į毩SWDŻ®▀BĮėĪóų¦│ųČÓ╠Ä└ĒŲ„Īóų¦│ųīŹ(sh©¬)Ģr(sh©¬)Ė·█ÖĪŻ
┤╦═ŌŻ¼įō╠Ä└ĒŲ„▀Ć╠ß╣®┴╦ę╗éĆ(g©©)┐╔▀xĄ─ā╚(n©©i)┤µ▒Żūo(h©┤)å╬į¬Ż©MPUŻ®Ż¼╠ß╣®Ą═│╔▒ŠĄ─š{(di©żo)įć/ūĘ█Ö╣”─▄║═╝»│╔Ą─ą▌├▀ĀŅæB(t©żi)Ż¼ęįį÷╝ėņ`╗ŅąįĪŻŪČ╚ļ╩Įķ_(k©Īi)░l(f©Ī)š▀īóĄ├ęį┐ņ╦┘įO(sh©©)ėŗ(j©¼)▓ó═Ų│÷┴Ņ╚╦▓Ü─┐Ą─ĮKČ╦«a(ch©Żn)ŲĘŻ¼Š▀éõūŅČÓĄ─╣”─▄ęį╝░ūŅĄ═Ą─╣”║─║═│▀┤ńĪŻ
╠Ä└Ē╝╝ąg(sh©┤)
Cortex-M4 ╠Ä└ĒŲ„ęčįO(sh©©)ėŗ(j©¼)×ķŠ▀ėą▀mė├ė┌öĄ(sh©┤)ūųą┼╠¢(h©żo)┐žųŲ╩ął÷(ch©Żng)Ą─ČÓĘNĖ▀ą¦
ą┼╠¢(h©żo)╠Ä└Ē╣”─▄ĪŻCortex-M4 ╠Ä└ĒŲ„▓╔ė├öU(ku©░)š╣Ą─å╬ų▄Ų┌│╦Ę©└█╝ė (MAC) ųĖ┴ŅĪóā×(y©Łu)╗»Ą─ SIMD ▀\(y©┤n)╦ŃĪó’¢║═▀\(y©┤n)╦ŃųĖ┴Ņ║═ę╗éĆ(g©©)┐╔▀xĄ─å╬Š½Č╚ĖĪ³c(di©Żn)å╬į¬ (FPU)ĪŻ▀@ą®╣”─▄ęį▒Ē¼F(xi©żn) ARM Cortex-M ŽĄ┴ą╠Ä└ĒŲ„╠žš„Ą─äō(chu©żng)ą┬╝╝ąg(sh©┤)×ķ╗∙ĄA(ch©│)ĪŻ

ų„ę¬╣”─▄
Å─łD╔Ž┐╔ęį┐┤│÷╚²š▀╣”─▄╔ŽĄ─«É═¼³c(di©Żn)ĪŻ╦³éāĄ─▓╗═¼³c(di©Żn)ę▓øQČ©┴╦╚²š▀Ą─▓╗═¼æ¬(y©®ng)ė├ł÷(ch©Żng)║ŽĪŻM4ŽÓ▒╚▌^Ū░ā╔š▀ų„ꬥ─ūā╗»į┌ė┌öĄ(sh©┤)ūų▀\(y©┤n)╦Ń─▄┴”╔ŽĄ─į÷ÅŖ(qi©óng)Ż¼į÷╝ė┴╦DSP▀\(y©┤n)╦ŃųĖ┴ŅĪóSIMDŻ©Single Instruction Multiple DataŻ¼å╬ųĖ┴ŅČÓöĄ(sh©┤)ō■(j©┤)┴„Ż®ųĖ┴Ņ╝»ĪóFPUŻ©ĖĪ³c(di©Żn)▀\(y©┤n)╦Ńå╬į¬Ż¼┐╔▀xŻ®ĪŻ
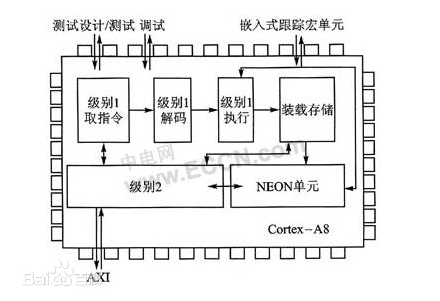
Å─łDųąūŃęį┐┤│÷M4ā╚(n©©i)║╦Ą─ÅŖ(qi©óng)┤¾Ż¼═¼Ģr(sh©¬)Cortex-M ŽĄ┴ą╠Ä└ĒŲ„Č╝╩ŪČ■▀M(j©¼n)ųŲŽ“╔Ž╝µ╚▌Ą─Ż¼▀@╩╣Ą├▄ø╝■ųžė├ęį╝░Å─ę╗éĆ(g©©) Cortex-M ╠Ä└ĒŲ„¤o(w©▓)┐p░l(f©Ī)š╣ĄĮ┴Ēę╗éĆ(g©©)│╔×ķ┐╔─▄(łD3)Ż║
Ž┬├µŠ═į÷ÅŖ(qi©óng)Ą─╚²éĆ(g©©)╣”─▄▀M(j©¼n)ąąšf(shu©Ł)├„Ż║
1ĪóDSPųĖ┴Ņ╝»
╦∙ų^╝»│╔DSP╣”─▄▓ó▓╗╩Ūšf(shu©Ł)M4ā╚(n©©i)║╦╩Ūę╗éĆ(g©©)M3+DSPĄ─ļp║╦╠Ä└ĒŲ„Ż©─┐Ū░éĆ(g©©)╚╦ų¬Ą└Ą─▀@ŅÉ(l©©i)╠Ä└ĒŲ„╩ŪTIĄ─▀_(d©ó)ĘęŲµŽĄ┴ąŻ¼ų„ę¬æ¬(y©®ng)ė├ė┌šZ(y©│)ę¶ĪóęĢŅlłDŽ±ėąĻP(gu©Īn)Ą─öĄ(sh©┤)ūųČÓ├Į¾wŅI(l©½ng)ė“Ż®ĪŻČ°╩Ūų╗╩Ūį÷╝ė┴╦DSP╣”─▄Ą─ųĖ┴Ņ╝»(å╬ų▄Ų┌Ą─▀\(y©┤n)╦ŃųĖ┴Ņ)Ż¼─▄į┌ę╗éĆ(g©©)ų▄Ų┌ā╚(n©©i)═Ļ│╔ųĖ┴Ņ▓┘ū„ĪŻį┌╣┘ĘĮĄ─CMSISś╦(bi©Īo)£╩(zh©│n)╣ż│╠Äņ(k©┤)ųąęčĮø(j©®ng)╝»│╔Ż¼┐╔ęįų▒Įė╩╣ė├Ż©ėąĻP(gu©Īn)ā╚(n©©i)╚▌į┌ęį║¾╬─š┬ųąĮķĮBŻ®ĪŻ
łD▒Ēš╣╩Š┴╦╠Ä└ĒŲ„▀\(y©┤n)ąąį┌ŽÓ═¼Ą─╦┘Č╚Ž┬Cortex - M3║═Cortex - M4į┌öĄ(sh©┤)ūųą┼╠¢(h©żo)╠Ä└Ē─▄┴”ĘĮ├µĄ─ŽÓī”(du©¼)ąį─▄▒╚▌^ĪŻ
į┌Ž┬├µĄ─öĄ(sh©┤)ūųŻ¼Y▌S┤·▒Ēł╠(zh©¬)ąąĮo│÷Ą─ėŗ(j©¼)╦Ńė├Ą─ŽÓī”(du©¼)Ą─ų▄Ų┌öĄ(sh©┤)ĪŻ ę“┤╦Ż¼čŁŁh(hu©ón)öĄ(sh©┤)įĮąĪŻ¼ąį─▄įĮ║├ĪŻęįCortex - M3ū„×ķģó┐╝Ż¼Cortex - M4Ą─ąį─▄ėŗ(j©¼)╦ŃŻ¼ąį─▄▒╚┤¾Ė┼×ķŲõų▄Ų┌ėŗ(j©¼)öĄ(sh©┤)Ą─Ą╣öĄ(sh©┤)ĪŻ┼e└²šf(shu©Ł)├„Ż¼PID╣”─▄Ż¼Cortex - M4Ą─ų▄Ų┌öĄ(sh©┤)╩Ū┼cCortex - M3Ą─╝s0.7▒ČŻ¼ę“┤╦ŽÓī”(du©¼)ąį─▄╩Ū1/0.7Ż¼╝┤1.4▒ČĪŻ
Cortex - MŽĄ┴ą16╬╗裣h(hu©ón)ėŗ(j©¼)öĄ(sh©┤)╣”─▄
Cortex - MŽĄ┴ą32╬╗裣h(hu©ón)ėŗ(j©¼)öĄ(sh©┤)╣”─▄
▀@║▄ŪÕ│■Ą─▒Ē├„Ż¼Cortex - M4į┌öĄ(sh©┤)ūųą┼╠¢(h©żo)╠Ä└ĒĘĮ├µī”(du©¼)▒╚Cortex - M3Ą─16╬╗╗“32╬╗▓┘ū„ėąų°║▄┤¾Ą─ā×(y©Łu)ä▌(sh©¼)ĪŻ
Cortex-M4ł╠(zh©¬)ąąĄ─╦∙ėąĄ─DSPųĖ┴Ņ╝»Č╝┐╔ęįį┌ę╗éĆ(g©©)ų▄Ų┌═Ļ│╔Ż¼Cortex - M3ąĶę¬ČÓéĆ(g©©)ųĖ┴Ņ║═ČÓéĆ(g©©)ų▄Ų┌▓┼─▄═Ļ│╔Ą─Ą╚ą¦╣”─▄ĪŻ╝┤╩╣╩ŪPID╦ŃĘ©——═©ė├DSP▀\(y©┤n)╦ŃųąūŅ║─┘M(f©©i)┘Yį┤Ą─╣żū„Ż¼Cortex - M4ę▓─▄╠ß╣®┴╦ę╗éĆ(g©©)1.4▒ČĄ─ąį─▄Ą├Ė─╔Ų ĪŻ┴Ēę╗éĆ(g©©)└²ūėŻ¼MP3ĮŌ┤aį┌Cortex-M3ąĶę¬20-25MhzŻ¼Č°į┌Cortex-M4ų╗ąĶę¬10-12MHzĪŻ
2. 32╬╗│╦Ę©└█╝ėŻ©MACŻ®
32╬╗│╦Ę©└█╝ėŻ©MACŻ®░³└©ą┬Ą─ųĖ┴Ņ╝»║═ßśī”(du©¼)Cortex - M4ė▓╝■ł╠(zh©¬)ąąå╬į¬Ą─ā×(y©Łu)╗»╦³╩Ū─▄ē“į┌å╬ų▄Ų┌ā╚(n©©i)═Ļ│╔ę╗éĆ(g©©) 32 × 32 + 64 - > 64 Ą─▓┘ū„ ╗“ ā╔éĆ(g©©)16 × 16 Ą─▓┘ū„ĪŻ╚ńŽ┬▒Ē┴ą│÷┴╦▀@éĆ(g©©)å╬į¬Ą─ėŗ(j©¼)╦Ń─▄┴”ĪŻ
3 .SIMD
(Single Instruction Multiple DataŻ¼å╬ųĖ┴ŅČÓöĄ(sh©┤)ō■(j©┤)┴„)─▄ē“Å═(f©┤)ųŲČÓéĆ(g©©)▓┘ū„öĄ(sh©┤)Ż¼▓ó░č╦³éā┤“░³į┌┤¾ą═╝─┤µŲ„Ą─ę╗ĮMųĖ┴Ņ╝»Ż¼└²Ż║3DNow!ĪóSSEĪŻęį═¼▓ĮĘĮ╩ĮŻ¼į┌═¼ę╗Ģr(sh©¬)ķgā╚(n©©i)ł╠(zh©¬)ąą═¼ę╗ŚlųĖ┴ŅĪŻ
SIMDį┌ąį─▄╔ŽĄ─ā×(y©Łu)ä▌(sh©¼)Ż║
ęį╝ėĘ©ųĖ┴Ņ×ķ└²Ż¼å╬ųĖ┴Ņå╬öĄ(sh©┤)ō■(j©┤)Ż©SISDŻ®Ą─CPUī”(du©¼)╝ėĘ©ųĖ┴Ņūg┤a║¾Ż¼ł╠(zh©¬)ąą▓┐╝■Ž╚įLå¢(w©©n)ā╚(n©©i)┤µŻ¼╚ĪĄ├Ą┌ę╗éĆ(g©©)▓┘ū„öĄ(sh©┤)Ż╗ų«║¾į┘ę╗┤╬įLå¢(w©©n)ā╚(n©©i)┤µŻ¼╚ĪĄ├Ą┌Č■éĆ(g©©)▓┘ū„öĄ(sh©┤)Ż╗ļS║¾▓┼─▄▀M(j©¼n)ąąŪ¾║═▀\(y©┤n)╦ŃĪŻČ°į┌SIMDą═Ą─CPUųąŻ¼ųĖ┴Ņūg┤a║¾ÄūéĆ(g©©)ł╠(zh©¬)ąą▓┐╝■═¼Ģr(sh©¬)įLå¢(w©©n)ā╚(n©©i)┤µŻ¼ę╗┤╬ąį½@Ą├╦∙ėą▓┘ū„öĄ(sh©┤)▀M(j©¼n)ąą▀\(y©┤n)╦ŃĪŻ▀@éĆ(g©©)╠ž³c(di©Żn)╩╣SIMD╠žäe▀m║Žė┌ČÓ├Į¾wæ¬(y©®ng)ė├Ą╚öĄ(sh©┤)ō■(j©┤)├▄╝»ą═▀\(y©┤n)╦ŃĪŻ
╚ńŻ║AMD╣½╦Šę²ęį×ķ║└Ą─3D NOW! ╝╝ąg(sh©┤)īŹ(sh©¬)┘|(zh©¼)Š═╩ŪSIMDŻ¼▀@╩╣K6-2Īó└ū°B(ni©Żo)ĪóČŠ²ł?zh©¬)Ä└ĒŲ„į┌ę¶ŅlĮŌ┤aĪóęĢŅl╗žĘ┼Īó3Dė╬æ“Ą╚æ¬(y©®ng)ė├ųą’@╩Š│÷ā×(y©Łu)«ÉĄ─ąį─▄ĪŻ
4.FPU
FPU╩ŪCortex - M4ĖĪ³c(di©Żn)▀\(y©┤n)╦ŃĄ─┐╔▀xå╬į¬ĪŻę“┤╦╦³╩Ūę╗éĆ(g©©)īŻ(zhu©Īn)ė├ė┌ĖĪ³c(di©Żn)╚╬äš(w©┤)Ą─å╬į¬ĪŻ▀@éĆ(g©©)å╬į¬═©▀^(gu©░)ė▓╝■╠ß╔²ąį─▄Ż¼─▄╠Ä└Ēå╬Š½Č╚ĖĪ³c(di©Żn)▀\(y©┤n)╦ŃŻ¼▓ó┼cIEEE 754ś╦(bi©Īo)£╩(zh©│n) ╝µ╚▌ĪŻ▀@═Ļ│╔┴╦ARMv7 - M╝▄śŗ(g©░u)å╬Š½Č╚ūā┴┐Ą─ĖĪ³c(di©Żn)öU(ku©░)š╣ĪŻFPUöU(ku©░)š╣┴╦╝─┤µŲ„Ą─│╠ą“─Żą═┼c░³║¼32éĆ(g©©)å╬Š½Č╚╝─┤µŲ„Ą─╝─┤µŲ„╬─╝■ĪŻ▀@ą®┐╔ęį▒╗┐┤ū„╩ŪŻ║
·16éĆ(g©©)64╬╗ļpūų╝─┤µŲ„Ż¼D0 - D15
·32éĆ(g©©)32╬╗å╬ūų╝─┤µŲ„Ż¼S0 - S31 įōFPU╠ß╣®┴╦╚²ĘN─Ż╩Į▀\(y©┤n)ū„Ż¼ęį▀mæ¬(y©®ng)Ė„ĘNæ¬(y©®ng)ė├
·╚½╝µ╚▌─Ż╩ĮŻ©į┌╚½╝µ╚▌─Ż╩ĮŻ¼F(xi©żn)PU╠Ä└Ē╦∙ėąĄ─▓┘ū„Č╝ū±čŁIEEE754Ą─ė▓╝■ś╦(bi©Īo)£╩(zh©│n)Ż®
·Flush-to-zero
ø_Ž┤ĄĮ┴Ń─Ż╩ĮŻ©įO(sh©©)ų├FZ╬╗ĖĪ³c(di©Żn)ĀŅæB(t©żi)║═┐žųŲ╝─┤µŲ„FPSCR [24]ĄĮflush-to-zero ─Ż╩ĮĪŻį┌┤╦─Ż╩ĮŽ┬Ż¼F(xi©żn)PU į┌▀\(y©┤n)╦Ńųąīó╦∙ėą▓╗š²│ŻĄ─▌ö╚ļ▓┘ū„öĄ(sh©┤)Ą─╦Ńąg(sh©┤)CDP▓┘ū„«ö(d©Īng)ū÷0.│²┴╦«ö(d©Īng)Å─┴Ń▓┘ū„öĄ(sh©┤)Ą─ĮY(ji©”)╣¹╩Ū║Ž▀mĄ─ŪķørĪŻVABSŻ¼VNEGŻ¼VMOV ▓╗Ģ■(hu©¼)▒╗«ö(d©Īng)ū÷╦Ńąg(sh©┤)CDPĄ─▀\(y©┤n)╦ŃŻ¼Č°Ūę▓╗╩▄flush-to-zero ─Ż╩Įė░ĒæĪŻĮY(ji©”)╣¹╩Ū╬óąĪĄ─Ż¼Š═Ž±į┌IEEE 754 ś╦(bi©Īo)£╩(zh©│n)Ą─├Ķ╩÷Ą──ŪśėŻ¼į┌─┐ś╦(bi©Īo)Š½Č╚į÷╝ėĄ─Ę∙Č╚ąĪė┌╦─╔ß╬Õ╚ļ║¾ūŅĄ═š²│ŻųĄŻ¼▒╗┴Ń╚Ī┤·ĪŻIDCĄ─ś╦(bi©Īo)ųŠ╬╗Ż¼F(xi©żn)PSCR [7]Ż¼▒Ē╩Š«ö(d©Īng)▌ö╚ļFlushĢr(sh©¬)ūā╗»ĪŻUFCś╦(bi©Īo)ųŠ╬╗Ż¼F(xi©żn)PSCR [3]Ż¼▒Ē╩Š«ö(d©Īng)FlushĮY(ji©”)╩°Ģr(sh©¬)ūā╗»Ż®
·─¼šJ(r©©n)Ą─NaN─Ż╩ĮŻ©DN╬╗Ą─įO(sh©©)ų├Ż¼F(xi©żn)PSCR [25]Ż¼Ģ■(hu©¼)▀M(j©¼n)╚ļNaNĄ──¼šJ(r©©n)─Ż╩ĮĪŻį┌▀@ĘN─Ż╩ĮŽ┬Ż¼╚ńī”(du©¼)╚╬║╬╦Ńąg(sh©┤)öĄ(sh©┤)ō■(j©┤)╠Ä└Ē▓┘ū„Ą─ĮY(ji©”)╣¹Ż¼╔µ╝░ę╗éĆ(g©©)▌ö╚ļNaNŻ¼╗“«a(ch©Żn)╔·ę╗éĆ(g©©)NaNĮY(ji©”)╣¹Ż¼Ģ■(hu©¼)ĘĄ╗ž─¼šJ(r©©n)Ą─NaNĪŻāH«ö(d©Īng)VABSŻ¼VNEGŻ¼VMOV▀\(y©┤n)╦ŃĢr(sh©¬)Ż¼Ęų?j©½n)?sh©┤)╬╗į÷╝ė▒Ż│ųĪŻ╦∙ėąŲõ╦¹Ą─CDP▀\(y©┤n)╦ŃĢ■(hu©¼)║÷┬į╦∙ėą▌ö╚ļNaNĄ─ąĪöĄ(sh©┤)╬╗Ą─ą┼ŽóŻ®ĪŻŠ▀¾wųĖ┴Ņšł(q©½ng)ūįąą▓ķ┐┤╩ųāį(c©©)ĪŻ
Cortex-M╣”─▄─ŻēK▓Ņ«É
ĪĪĪĪė╔ė┌CM1ų„ę¬╩Ūė├į┌FPGA«a(ch©Żn)ŲĘųąŻ¼╣╩Ž┬├µī”(du©¼)▒╚║÷┬įCM1ĪŻ╬ęéāų¬Ą└CM╠Ä└ĒŲ„╩ŪŽ“Ž┬╝µ╚▌Ą─Ż¼╣╩CM╣”─▄─ŻēK╩ŪļSų°░µ▒ŠĄ─╔²╝ē(j©¬)Č°ų▓Įį÷╝ėĄ─Ż¼╬ęéāų▓ĮÅ─ūŅĄ═░µ▒Šķ_(k©Īi)╩╝ī”(du©¼)▒╚ĪŻ
2.1 CM0 vs CM0+
ĪĪĪĪŽ╚üĒ(l©ói)┴─┴─CM0┼cCM0+Ż¼Å─ūŅ╗∙£╩(zh©│n)Ą─CM0─ŻēK┐┤ŲŻ║

- ARMv6-M CPUā╚(n©©i)║╦Ż║ARM╣½╦Šė┌2007─Ļ═Ų│÷Ą─ā╚(n©©i)║╦ĪŻ±T·ųZę└┬³¾wŽĄĮY(ji©”)śŗ(g©░u)Ż¼3╝ē(j©¬)┴„╦«ŠĆŻ¼ų¦│ų┤¾▓┐ĘųThumb║═ąĪ▓┐ĘųThumb-2ųĖ┴Ņ╝»Ż¼╦∙ėąųĖ┴Ņę╗╣▓57ŚlĪŻ┤╦═Ō▀Ćā╚(n©©i)ŪČ32-bitĘĄ╗žĮY(ji©”)╣¹Ą─ė▓╝■│╦Ę©Ų„ĪŻ
- NVICŪČ╠ūŽ“┴┐ųąöÓ┐žųŲŲ„Ż║ė├ė┌CPUį┌š²│ŻRun─Ż╩ĮŽ┬ųąöÓ╣▄└ĒĪŻūŅ┤¾ų¦│ų32éĆ(g©©)═Ō▓┐ųąöÓŻ¼═Ō▓┐ųąöÓ┐╔įO(sh©©)4╝ē(j©¬)ōīš╝ā×(y©Łu)Ž╚╝ē(j©¬)Ż©2bitŻ®ĪŻ
- WICåŠąčųąöÓ┐žųŲŲ„Ż║ė├ė┌CPUį┌Ą═╣”║─Sleep─Ż╩ĮŽ┬ųąöÓ╣▄└ĒĪŻ
- AHB-Lite┐éŠĆŻ║ę╗Śl32bit
AMBA-3ś╦(bi©Īo)£╩(zh©│n)Ą─Ė▀ąį─▄system┐éŠĆžō(f©┤)ž¤(z©”)╦∙ėąFlashĪóSRAMųąųĖ┴Ņ║═öĄ(sh©┤)ō■(j©┤)┤µ╚ĪĪŻ
- š{(di©żo)įć─ŻēKŻ║0-4éĆ(g©©)ė▓╝■öÓ³c(di©Żn)BreakpointŻ¼0-2éĆ(g©©)öĄ(sh©┤)ō■(j©┤)▒O(ji©Īn)£y(c©©)³c(di©Żn)WatchpointĪŻ
- DAPš{(di©żo)įćĮė┐┌Ż║═©▀^(gu©░)DAP─ŻēKų¦│ųJTAG║═SWDĮė┐┌ĪŻ

ĪĪĪĪ─Ū├┤CM0+ĄĮĄūĖ─▀M(j©¼n)┴╦╩▓├┤Ż┐
- ARMv6-M CPUā╚(n©©i)║╦Ż║┴„╦«ŠĆĖ─×ķ2╝ē(j©¬)Ż©║▄ČÓ8bit MCUČ╝╩Ū2╝ē(j©¬)┴„╦«ŠĆŻ¼ų„ę¬ė├ė┌ĮĄĄ═╣”║─Ż®
- NVICŪČ╠ūŽ“┴┐ųąöÓ┐žųŲŲ„Ż║į÷╝ė┴╦VTOR╝┤ųąöÓųžČ©Ž“╣”─▄ĪŻ
ĪĪĪĪ─Ū├┤CM0+ĄĮĄūį÷╝ė┴╦╩▓├┤Ż┐
- MPU┤µā”(ch©│)Ų„▒Żūo(h©┤)å╬į¬Ż║╠ß╣®ė▓╝■ĘĮ╩Į╣▄└Ē║═▒Żūo(h©┤)ā╚(n©©i)┤µŻ¼┐žųŲįLå¢(w©©n)ÖÓ(qu©ón)Ž▐Ż¼ūŅ┤¾┐╔īóā╚(n©©i)┤µĘų×ķ8*8éĆ(g©©)regionĪŻā╚(n©©i)┤µįĮÖÓ(qu©ón)įLå¢(w©©n)Ż¼īóĘĄ╗žMemManage
FaultĪŻ
- MTBŲ¼╔ŽĖ·█Öå╬į¬Ż║ė├涾w“×(y©żn)Ė³║├Ą─Ą─Ė·█Öš{(di©żo)įćŻ¼ā×(y©Łu)╗»Ą─«É│Ż▓Č½@ÖC(j©®)ųŲŻ¼┐╔ęįĖ³┐ņĄžČ©╬╗bugĪŻ
- Fast I/OŻ║┐╔å╬ų▄Ų┌įLå¢(w©©n)Ą─┐ņ╦┘I(m©Żi)/O┐┌Ż¼Ė³ęūė┌Bit-bangingŻ©▒╚╚ńGPIO─ŻöMSPIĪóIICģf(xi©”)ūhŻ®ĪŻ
2.2 CM0+ vs CM3

ĪĪĪĪŪ░├µ▒╚▌^═Ļ┴╦CM0┼cCM0+Ż¼į┘üĒ(l©ói)┐┤┐┤CM3▒╚CM0+į÷ÅŖ(qi©óng)į┌┴╦──└’Ż║
ĪĪĪĪ─Ū├┤CM3ĄĮĄūĖ─▀M(j©¼n)┴╦╩▓├┤Ż┐
- ARMv7-M CPUā╚(n©©i)║╦Ż║ARM╣½╦Šė┌2004─Ļ═Ų│÷Ą─ā╚(n©©i)║╦ĪŻ╣■Ę¾wŽĄĮY(ji©”)śŗ(g©░u)Ż¼3╝ē(j©¬)┴„╦«ŠĆ+Ęųų¦ŅA(y©┤)£y(c©©)Ż¼ų¦│ų╚½▓┐Ą─Thumb║═Thumb-2ųĖ┴Ņ╝»ĪŻā╚(n©©i)ŪČ32-bitė▓╝■│╦Ę©Ų„┐╔ĘĄ╗ž64-bit▀\(y©┤n)╦ŃĮY(ji©”)╣¹Ż¼Ūęą┬į÷32-bitė▓╝■│²Ę©Ų„ĪŻ
- NVICŪČ╠ūŽ“┴┐ųąöÓ┐žųŲŲ„Ż║ūŅ┤¾ų¦│ų240éĆ(g©©)═Ō▓┐ųąöÓŻ¼ųąöÓā×(y©Łu)Ž╚╝ē(j©¬)┐╔ĘųĮMŻ©ōīš╝ā×(y©Łu)Ž╚╝ē(j©¬)ĪóĒææ¬(y©®ng)ā×(y©Łu)Ž╚╝ē(j©¬)Ż®Ż¼8bitā×(y©Łu)Ž╚╝ē(j©¬)įO(sh©©)ų├Ż©ūŅ┤¾128╝ē(j©¬)ōīš╝ā×(y©Łu)Ž╚╝ē(j©¬)(ī”(du©¼)æ¬(y©®ng)ūŅąĪ2╝ē(j©¬)Ēææ¬(y©®ng)ā×(y©Łu)Ž╚╝ē(j©¬))Ż¼ūŅ┤¾256╝ē(j©¬)Ēææ¬(y©®ng)ā×(y©Łu)Ž╚╝ē(j©¬)(ī”(du©¼)æ¬(y©®ng)¤o(w©▓)ōīš╝ā×(y©Łu)Ž╚╝ē(j©¬))Ż®ĪŻ
- 3x AHB-Lite┐éŠĆŻ║│²┴╦įŁsystem┐éŠĆžō(f©┤)ž¤(z©”)SRAM┤µ╚Ī═ŌŻ¼▀Ćą┬į÷ā╔ŚlICodeĪóDCode┐éŠĆĘųäe═Ļ│╔Flash╔ŽųĖ┴Ņ║═öĄ(sh©┤)ō■(j©┤)┤µ╚ĪĪŻ
- š{(di©żo)įć─ŻēKŻ║0-8éĆ(g©©)ė▓╝■öÓ³c(di©Żn)BreakpointŻ¼0-4éĆ(g©©)öĄ(sh©┤)ō■(j©┤)▒O(ji©Īn)£y(c©©)³c(di©Żn)WatchpointĪŻ
- ITM/ETMĖ·█Öå╬į¬Ż║ITMĖ³║├Ąžų¦│ųprintf’L(f©źng)Ė±debugŻ¼ETM╠ß╣®īŹ(sh©¬)Ģr(sh©¬)ųĖ┴Ņ║═öĄ(sh©┤)ō■(j©┤)Ė·█ÖĪŻ
ĪĪĪĪ─Ū├┤CM3ĄĮĄūį÷╝ė┴╦╩▓├┤Ż┐
ĪĪĪĪŅ~Ż¼CM3ŽÓ▒╚CM0+▓óø](m©”i)ėąį÷╝ė╩▓├┤¬Ü(d©▓)ėą─ŻēKŻ¼Ę┤Ą╣╩Ū╔┘┴╦Fast I/O PortŻ¼īŹ(sh©¬)ļH╔ŽFast I/O Port╩ŪCM╝ęūÕ└’CM0+╦∙¬Ü(d©▓)ėąĄ──ŻēKĪŻ
2.3 CM3 vs CM4

ĪĪĪĪŪ░├µ▒╚▌^═Ļ┴╦CM0+┼cCM3Ż¼į┘üĒ(l©ói)┐┤┐┤CM4▒╚CM3į÷ÅŖ(qi©óng)į┌┴╦──└’Ż║
ĪĪĪĪ─Ū├┤CM4ĄĮĄūĖ─▀M(j©¼n)┴╦╩▓├┤Ż┐
- ARMv7E-M CPUā╚(n©©i)║╦Ż║į÷╝ė┴╦DSPŽÓĻP(gu©Īn)ųĖ┴Ņų¦│ųĪŻ
ĪĪĪĪ─Ū├┤CM4ĄĮĄūį÷╝ė┴╦╩▓├┤Ż┐
- DSPöĄ(sh©┤)ūųą┼╠¢(h©żo)╠Ä└Ēå╬į¬Ż║ą┬į÷ų¦│ųå╬ų▄Ų┌16/32-bit MACĪódual 16-bit
MAC, 8/16-bit SIMD╦ŃĘ©Ą─öĄ(sh©┤)ūųą┼╠¢(h©żo)╠Ä└Ēå╬į¬ĪŻ
- FPUĖĪ³c(di©Żn)▀\(y©┤n)╦Ńå╬į¬Ż║ą┬į÷å╬Š½Č╚Ż©floatą═Ż®╝µ╚▌IEEE-754ś╦(bi©Īo)£╩(zh©│n)Ą─ĖĪ³c(di©Żn)▀\(y©┤n)╦Ńå╬į¬Ż©VFPv4-SPŻ®ĪŻ
2.4 CM4 vs CM7
ĪĪĪĪŪ░├µ▒╚▌^═Ļ┴╦CM3┼cCM4Ż¼į┘üĒ(l©ói)┐┤┐┤CM7▒╚CM4į÷ÅŖ(qi©óng)į┌┴╦──└’Ż║
ĪĪĪĪ─Ū├┤CM7ĄĮĄūĖ─▀M(j©¼n)┴╦╩▓├┤Ż┐
- ARMv7E-M CPUā╚(n©©i)║╦Ż║6╝ē(j©¬)┴„╦«ŠĆ+Ęųų¦ŅA(y©┤)£y(c©©)ĪŻ
- 2x AHB-Lite┐éŠĆŻ║Š½║å(ji©Żn)×ķ2ŚlAHB┐éŠĆŻ¼ŲõųąAHB-P═ŌįO(sh©©)Įė┐┌═Ļ│╔įŁüĒ(l©ói)system┐éŠĆ╣”─▄, AHB-SÅ─ī┘Įė┐┌žō(f©┤)ž¤(z©”)═Ō▓┐┐éŠĆ┐žųŲŲ„Ż©╚ńDMAŻ®╣”─▄ęį╝░┼cTCMĮė┐┌╣”─▄ĪŻ
- MPU┤µā”(ch©│)Ų„▒Żūo(h©┤)å╬į¬Ż║ūŅ┤¾┐╔īóā╚(n©©i)┤µĘų×ķ16*8éĆ(g©©)regionĪŻ
- FPUĖĪ³c(di©Żn)▀\(y©┤n)╦Ńå╬į¬Ż║ą┬į÷ļpŠ½Č╚Ż©doubleą═Ż®╝µ╚▌IEEE-754ś╦(bi©Īo)£╩(zh©│n)Ą─ĖĪ³c(di©Żn)▀\(y©┤n)╦Ńå╬į¬Ż©VFPv5Ż®ĪŻ

ĪĪĪĪ─Ū├┤CM7ĄĮĄūį÷╝ė┴╦╩▓├┤Ż┐
- I/D-CacheŠÅ┤µģ^(q©▒)Ż║╝┤╩Ū╬ęéā═©│Ż└ĒĮŌĄ─L1
CacheŻ¼├┐éĆ(g©©)Cache┤¾ąĪ×ķ4-64KBĪŻ
- I/D-TCMŠo├▄±Ņ║Ž┤µā”(ch©│)Ų„Ż║Šo├▄Ą─┼c╠Ä└ĒŲ„ā╚(n©©i)║╦ŽÓ±Ņ║ŽĄ─RAMŻ¼╠ß╣®┼cCacheŽÓ«ö(d©Īng)?sh©┤)─ąį─▄Ż¼Ą½▒╚CacheĖ³Š▀┤_Č©ąįŻ¼memoryūŅ┤¾Š∙×ķ16MBĪŻ
- ECC╠žąįŻ║ī”(du©¼)L1
Cache╠ß╣®Õe(cu©░)š`ąŻš²║═╗ųÅ═(f©┤)╣”─▄Ż¼╠ßĖ▀ŽĄĮy(t©»ng)Ą─┐╔┐┐ąįĪŻ
- AXI-M┐éŠĆŻ║╗∙ė┌AMBA
4Ą─64bit AXI┐éŠĆŻ¼ė├ė┌ų¦│ųÆņį┌ŽĄĮy(t©»ng)╔ŽĄ─L2
memoryĪŻ
- ūŅĮ³į┌ĻP(gu©Īn)ūóCortex-M╠Ä└ĒŲ„Ż¼ßśī”(du©¼)─┐Ū░▀M(j©¼n)╚ļ┤¾▒ŖęĢę░Ą─M0ĪóM3ĪóM4ū÷┴╦╚ńŽ┬║å(ji©Żn)å╬ī”(du©¼)▒╚Ż¼ā╚(n©©i)╚▌üĒ(l©ói)ūįARMĄ╚╣┘ŠW(w©Żng)Ż¼▀@└’āHāH╩Ūš¹└Ē┴╦Ž┬Ż¼┐┤ŲüĒ(l©ói)Ė³ų▒ė^³c(di©Żn)Ż¼║Ū║ŪĪŻ
-
- Cortex-M ŽĄ┴ąßśī”(du©¼)│╔▒Š║═╣”║─├¶ĖąĄ─ MCU ║═ĮKČ╦æ¬(y©®ng)ė├Ż©╚ńųŪ─▄£y(c©©)┴┐Īó╚╦ÖC(j©®)Įė┐┌įO(sh©©)éõĪóŲ¹▄ć(ch©ź)║═╣żśI(y©©)┐žųŲŽĄĮy(t©»ng)Īó┤¾ą═╝ęė├ļŖŲ„ĪóŽ¹┘M(f©©i)ąį«a(ch©Żn)ŲĘ║═ßt(y©®)»¤Ų„ąĄŻ®Ą─╗ņ║Žą┼╠¢(h©żo)įO(sh©©)éõ▀M(j©¼n)ąą▀^(gu©░)ā×(y©Łu)╗»ĪŻ.
- ę╗Īó▒╚▌^Cortex-M ╠Ä└ĒŲ„
- Cortex-M ŽĄ┴ą╠Ä└ĒŲ„Č╝╩ŪČ■▀M(j©¼n)ųŲŽ“╔Ž╝µ╚▌Ą─Ż¼▀@╩╣Ą├▄ø╝■ųžė├ęį╝░Å─ę╗éĆ(g©©) Cortex-M ╠Ä└ĒŲ„¤o(w©▓)┐p░l(f©Ī)š╣ĄĮ┴Ēę╗éĆ(g©©)│╔×ķ┐╔─▄ĪŻ
- M Cortex-M ╝╝ąg(sh©┤)
- CMSIS
- ARM Cortex ╬ó┐žųŲŲ„▄ø╝■Įė┐┌ś╦(bi©Īo)£╩(zh©│n) (CMSIS)╩Ū Cortex-M ╠Ä└ĒŲ„ŽĄ┴ąĄ─┼c╣®æ¬(y©®ng)╔╠¤o(w©▓)ĻP(gu©Īn)Ą─ė▓╝■│ķŽ¾īėĪŻ ╩╣ė├ CMSISŻ¼┐╔ęį×ķĮė┐┌═ŌįO(sh©©)ĪóīŹ(sh©¬)Ģr(sh©¬)▓┘ū„ŽĄĮy(t©»ng)║═ųąķg╝■īŹ(sh©¬)¼F(xi©żn)ę╗ų┬Ūę║å(ji©Żn)å╬Ą─▄ø╝■Įė┐┌Ż¼Å─Č°║å(ji©Żn)╗»▄ø╝■Ą─ųžė├Īó┐sČ╠ą┬╬ó┐žųŲŲ„ķ_(k©Īi)░l(f©Ī)╚╦åTĄ─īW(xu©”)┴Ģ(x©¬)▀^(gu©░)│╠Ż¼▓ó┐sČ╠ą┬«a(ch©Żn)ŲĘĄ─╔Ž╩ąĢr(sh©¬)ķgĪŻ
- ╔Ņ╚ļŻ║ŪČ╠ū╩Ė┴┐ųąöÓ┐žųŲŲ„ (NVIC)
- NVIC ╩Ū Cortex-M ╠Ä└ĒŲ„▓╗┐╔╗“╚▒Ą─▓┐ĘųŻ¼╦³×ķ╠Ä└ĒŲ„╠ß╣®┴╦ū┐įĮĄ─ųąöÓ╠Ä└Ē─▄┴”ĪŻ
- Cortex-M ╠Ä└ĒŲ„╩╣ė├ę╗éĆ(g©©)╩Ė┴┐▒ĒŻ¼Ųõųą░³║¼ę¬×ķ╠žČ©ųąöÓ╠Ä└Ē│╠ą“ł╠(zh©¬)ąąĄ─║»öĄ(sh©┤)Ą─ĄžųĘĪŻĮė╩▄ųąöÓĢr(sh©¬)Ż¼╠Ä└ĒŲ„Ģ■(hu©¼)Å─įō╩Ė┴┐▒Ēųą╠ß╚ĪĄžųĘĪŻ
- ×ķ┴╦£p╔┘ķT(m©”n)öĄ(sh©┤)▓óį÷ÅŖ(qi©óng)ŽĄĮy(t©»ng)ņ`╗ŅąįŻ¼Cortex-M ╠Ä└ĒŲ„╩╣ė├ę╗éĆ(g©©)╗∙ė┌Č茯Ą─«É│Ż─Żą═ĪŻ│÷¼F(xi©żn)«É│ŻĢr(sh©¬)Ż¼ŽĄĮy(t©»ng)Ģ■(hu©¼)īóĻP(gu©Īn)µI═©ė├╝─┤µŲ„═Ų╦═ĄĮČ茯╔ŽĪŻ═Ļ│╔╚ļŚŻ║═ųĖ┴Ņ╠ß╚Ī║¾Ż¼īół╠(zh©¬)ąąųąöÓĘ■äš(w©┤)└²│╠╗“╣╩šŽ╠Ä└Ē│╠ą“Ż¼╚╗║¾ūįäė(d©░ng)▀ĆįŁ╝─┤µŲ„ęį╩╣ųąöÓĄ─│╠ą“╗ųÅ═(f©┤)š²│Żł╠(zh©¬)ąąĪŻ╩╣ė├┤╦ĘĮĘ©Ż¼▒Ѥo(w©▓)ąĶŠÄīæ(xi©¦)ģRŠÄŲ„░³čbŲ„┴╦Ż©Č°▀@╩Ūī”(du©¼)╗∙ė┌ C šZ(y©│)čįĄ─é„Įy(t©»ng)ųąöÓĘ■äš(w©┤)└²│╠ł╠(zh©¬)ąąČ茯▓┘ū„╦∙▒žąĶĄ─Ż®Ż¼Å─Č°╩╣Ą├æ¬(y©®ng)ė├│╠ą“Ą─ķ_(k©Īi)░l(f©Ī)ūāĄ├ĘŪ│Ż╚▌ęūĪŻNVICų¦│ųųąöÓŪČ╠ūŻ©╚ļŚŻŻ®Ż¼Å─Č°į╩įS═©▀^(gu©░)▀\(y©┤n)ė├▌^Ė▀Ą─ā×(y©Łu)Ž╚╝ē(j©¬)üĒ(l©ói)▌^įńĄž×ķ─│éĆ(g©©)ųąöÓ╠ß╣®Ę■äš(w©┤)ĪŻ
- į┌ė▓╝■ųą═Ļ│╔ī”(du©¼)ųąöÓĄ─Ēææ¬(y©®ng)
- Cortex-M ŽĄ┴ą╠Ä└ĒŲ„Ą─ųąöÓĒææ¬(y©®ng)╩ŪÅ─░l(f©Ī)│÷ųąöÓą┼╠¢(h©żo)ĄĮł╠(zh©¬)ąąųąöÓĘ■äš(w©┤)└²│╠Ą─ų▄Ų┌öĄ(sh©┤)ĪŻ╦³░³└©Ż║
- Öz£y(c©©)ųąöÓ
- ▒│ī”(du©¼)▒│╗“▀tĄĮųąöÓĄ─ūŅ╝č╠Ä└ĒŻ©ģóęŖ(ji©żn)Ž┬╬─Ż®
- ╠ß╚Ī╩Ė┴┐ĄžųĘ
- īóęūōpē─Ą─╝─┤µŲ„╚ļŚŻ
- ╠°▐D(zhu©Żn)ĄĮųąöÓ╠Ä└Ē│╠ą“
- ▀@ą®╚╬äš(w©┤)į┌ė▓╝■ųął╠(zh©¬)ąąŻ¼▓óŪę░³║¼į┌×ķ Cortex-M ╠Ä└ĒŲ„ł¾(b©żo)│÷Ą─ųąöÓĒææ¬(y©®ng)ų▄Ų┌Ģr(sh©¬)ķgųąĪŻį┌Ųõ╦¹įSČÓ¾wŽĄĮY(ji©”)śŗ(g©░u)ųąŻ¼▀@ą®╚╬äš(w©┤)▒žĒÜį┌▄ø╝■Ą─ųąöÓ╠Ä└Ē│╠ą“ųął╠(zh©¬)ąąŻ¼Å─Č°ę²Ųčė▀t▓ó╩╣Ą├▀^(gu©░)│╠╩«ĘųÅ═(f©┤)ļsĪŻ
-
- NVIC ųąĄ─╬▓µ£
- į┌▒│ī”(du©¼)▒│ųąöÓĄ─ŪķørŽ┬Ż¼é„Įy(t©»ng)ŽĄĮy(t©»ng)Ģ■(hu©¼)ųžÅ═(f©┤)═Ļš¹Ą─ĀŅæB(t©żi)▒Ż┤µ║═▀ĆįŁų▄Ų┌ā╔┤╬Ż¼Å─Č°ī¦(d©Żo)ų┬Ė³Ė▀Ą─čė▀tĪŻCortex-M╠Ä└ĒŲ„═©▀^(gu©░)į┌ NVIC
ė▓╝■ųąīŹ(sh©¬)¼F(xi©żn)╬▓µ£╝╝ąg(sh©┤)║å(ji©Żn)╗»┴╦╗Ņäė(d©░ng)ųąöÓ║═ÆņŲĄ─ųąöÓų«ķgĄ─▐D(zhu©Żn)ōQĪŻ╠Ä└ĒŲ„ĀŅæB(t©żi)Ģ■(hu©¼)į┌▒╚▄ø╝■īŹ(sh©¬)¼F(xi©żn)Ģr(sh©¬)ķgĖ³╔┘Ą─ų▄Ų┌ā╚(n©©i)ūįäė(d©░ng)▒Ż┤µį┌ųąöÓŚl─┐╔Ž▓óį┌ųąöÓ═╦│÷Ģr(sh©¬)▀ĆįŁŻ¼Å─Č°’@ų°╠ß╔²Ą═ MHz ŽĄĮy(t©»ng)Ą─ąį─▄ĪŻ
-
- NVIC ī”(du©¼)▀tĄĮĄ─▌^Ė▀ā×(y©Łu)Ž╚╝ē(j©¬)ųąöÓĄ─Ēææ¬(y©®ng)
- ╚ń╣¹į┌×ķ╔Žę╗éĆ(g©©)ųąöÓł╠(zh©¬)ąąČ茯═Ų╦═Ų┌ķg▌^Ė▀ā×(y©Łu)Ž╚╝ē(j©¬)Ą─ųąöÓ▀tĄĮŻ¼NVIC Ģ■(hu©¼)┴ó╝┤╠ß╚Īą┬Ą─╩Ė┴┐ĄžųĘüĒ(l©ói)×ķÆņŲĄ─ųąöÓ╠ß╣®Ę■äš(w©┤)Ż¼╚ń╔Ž╦∙╩ŠĪŻCortex-M
NVIC ī”(du©¼)▀@ą®┐╔─▄ąį╠ß╣®Š▀ėą┤_Č©ąįĄ─Ēææ¬(y©®ng)▓óų¦│ų▀tĄĮ║═ōīš╝ĪŻ
-
- NVIC ▀M(j©¼n)ąąĄ─ČčŚŻÅŚ│÷ōīš╝
- ═¼śėŻ¼╚ń╣¹«É│ŻĄĮ▀_(d©ó)Ż¼NVIC īóĘ┼ŚēČčŚŻÅŚ│÷▓ó┴ó╝┤×ķą┬Ą─ųąöÓ╠ß╣®Ę■äš(w©┤)Ż¼╚ń╔Ž╦∙╩ŠĪŻ═©▀^(gu©░)ōīš╝▓óŪąōQĄĮĄ┌Č■éĆ(g©©)ųąöÓČ°▓╗═Ļ│╔ĀŅæB(t©żi)▀ĆįŁ║═▒Ż┤µŻ¼NVIC ęįŠ▀ėą┤_Č©ąįĄ─ĘĮ╩ĮīŹ(sh©¬)¼F(xi©żn)┴╦┐sČ╠čė▀tĪŻ
į┘üĒ(l©ói)šf(shu©Ł)šf(shu©Ł)ARM7Ż¼ARM9ŽĄ┴ąŻ¼
ARM9
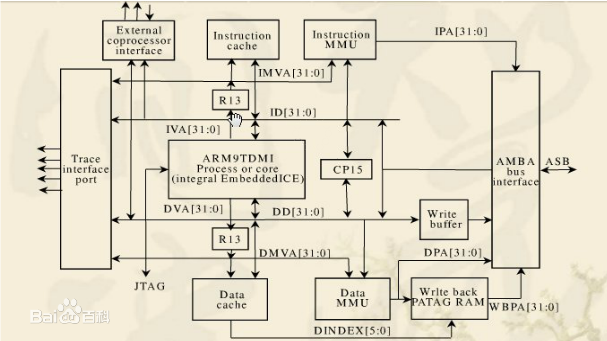
ARM9ŽĄ┴ą╠Ä└ĒŲ„╩Ūėóć°(gu©«)ARM╣½╦ŠįO(sh©©)ėŗ(j©¼)Ą─ų„┴„ŪČ╚ļ╩Į╠Ä└ĒŲ„Ż¼ų„ę¬░³└©ARM9TDMI║═ARM9E-SĄ╚ŽĄ┴ąĪŻ
╗∙▒ŠĖ┼╩÷
ARM9▓╔ė├╣■Ę¾wŽĄĮY(ji©”)śŗ(g©░u)Ż¼ųĖ┴Ņ║═öĄ(sh©┤)ō■(j©┤)Ęųī┘▓╗═¼Ą─┐éŠĆŻ¼┐╔ęį▓óąą╠Ä└ĒĪŻį┌┴„╦«ŠĆ╔ŽŻ¼ARM7╩Ū╚²╝ē(j©¬)┴„╦«ŠĆŻ¼ARM9╩Ū╬Õ╝ē(j©¬)┴„╦«ŠĆĪŻė╔ė┌ĮY(ji©”)śŗ(g©░u)▓╗═¼Ż¼ARM7Ą─ł╠(zh©¬)ąąą¦┬╩Ą═ė┌ARM9ĪŻŲĮĢr(sh©¬)╦∙šf(shu©Ł)Ą─ARM7ĪóARM9īŹ(sh©¬)ļH╔ŽųĖĄ─╩ŪARM7TDMIĪóARM9TDMI▄ø║╦Ż¼▀@ĘN╠Ä└ĒŲ„▄ø║╦▓ó▓╗ĦėąMMU║═cacheŻ¼▓╗─▄ē“▀\(y©┤n)ąąųT╚ńlinux▀@śėĄ─ŪČ╚ļ╩Į▓┘ū„ŽĄĮy(t©»ng)ĪŻČ°ARM╣½╦Šī”(du©¼)▀@ĘN╝▄śŗ(g©░u)▀M(j©¼n)ąą┴╦öU(ku©░)š╣Ż¼╦∙ęįėą┴╦ARM710TĪóARM720TĪóARM920TĪóARM922TĄ╚ĦėąMMU║═cacheĄ─╠Ä└ĒŲ„ā╚(n©©i)║╦ĪŻ
ų„ę¬╠žąįŠÄ▌ŗ
╚┌║Ž┴╦ARM920T™ ARM® Thumb® ╠Ä└ĒŲ„
– ╣żū„ė┌180 MHzĢr(sh©¬)ąį─▄Ė▀▀_(d©ó)200 MIPSŻ¼┤µā”(ch©│)Ų„╣▄└Ēå╬į¬
– 16-K ūų╣Ø(ji©”)Ą─öĄ(sh©┤)ō■(j©┤)ŠÅ┤µŻ¼16-Kūų╣Ø(ji©”)Ą─ųĖ┴ŅŠÅ┤µŻ¼īæ(xi©¦)ŠÅø_Ų„
– ║¼ėąš{(di©żo)įćą┼Ą└Ą─ā╚(n©©i)▓┐Ę┬šµŲ„
– ųąĄ╚ęÄ(gu©®)─ŻĄ─ŪČ╚ļ╩Į║Ļå╬į¬ĮY(ji©”)śŗ(g©░u)( āHßśī”(du©¼)256 BGA ĘŌčb)
· Ą═╣”║─Ż║VDDCOREļŖ┴„×ķ30.4 mA ┤²ÖC(j©®)─Ż╩ĮļŖ┴„×ķ3.1 mA
· ĖĮ╝ėĄ─ŪČ╚ļ╩Į┤µā”(ch©│)Ų„
– SRAM×ķ16K Ż╗ROM×ķ128K
· ═Ō▓┐┐éŠĆĮė┐┌(EBI)
– ų¦│ųSDRAMŻ¼ņoæB(t©żi)┤µā”(ch©│)Ų„Ż¼ Burst FlashŻ¼¤o(w©▓)┐p▀BĮėĄ─CompactFlash®Ż¼
SmartMedia™╝░NAND Flash
· ╠ßĖ▀ąį─▄Č°╩╣ė├Ą─ŽĄĮy(t©»ng)═ŌįO(sh©©)Ż║
– į÷ÅŖ(qi©óng)Ą─Ģr(sh©¬)ńŖ░l(f©Ī)╔·Ų„┼cļŖį┤╣▄└Ē┐žųŲŲ„
– ā╔éĆ(g©©)ėąļpPLLĄ─Ų¼╔Žš±╩ÄŲ„
– Ą═╦┘Ą─Ģr(sh©¬)ńŖ▓┘ū„─Ż╩Į┼c▄ø╝■╣”║─ā×(y©Łu)╗»─▄┴”
– ╦─éĆ(g©©)┐╔ŠÄ│╠Ą─═Ō▓┐Ģr(sh©¬)ńŖą┼╠¢(h©żo)
– ░³└©ų▄Ų┌ąįųąöÓĪó┐┤ķT(m©”n)╣Ę╝░Ą┌Č■ėŗ(j©¼)öĄ(sh©┤)Ų„Ą─ŽĄĮy(t©»ng)Č©Ģr(sh©¬)Ų„
– ėął¾(b©żo)Š»ųąöÓĄ─īŹ(sh©¬)Ģr(sh©¬)Ģr(sh©¬)ńŖ
– š{(di©żo)įćå╬į¬Īóā╔ŠĆUART▓óų¦│ųš{(di©żo)įćą┼Ą└
– ėą8 éĆ(g©©)ā×(y©Łu)Ž╚╝ē(j©¬)Ą─Ė▀╝ē(j©¬)ųąöÓ┐žųŲŲ„Ż¼¬Ü(d©▓)┴óĄ─┐╔Ų┴▒╬ųąöÓį┤Ż¼é╬ųąöÓ▒Żūo(h©┤)
– 7éĆ(g©©)═Ō▓┐ųąöÓį┤╝░1 éĆ(g©©)┐ņ╦┘ųąöÓį┤
– ėą122éĆ(g©©)┐╔ŠÄ│╠I/O┐┌ŠĆĄ─╦─éĆ(g©©)32 ╬╗PIO┐žųŲŲ„Ż¼Ė„ŠĆŠ∙ėą▌ö╚ļūā╗»ųąöÓ╝░ķ_(k©Īi)┬®─▄┴”
– 20═©Ą└Ą─═ŌįO(sh©©)öĄ(sh©┤)ō■(j©┤)┐žųŲŲ„(DMA)
· 10/100 Base-T ą═ęį╠½ŠW(w©Żng)┐©Įė┐┌
– ¬Ü(d©▓)┴óĄ─├Į¾wĮė┐┌(MII)╗“║å(ji©Żn)╗»Ą─¬Ü(d©▓)┴ó├Į¾wĮė┐┌(RMII)
– ī”(du©¼)ė┌Įė╩š┼c░l(f©Ī)╦═ėą╝»│╔Ą─28 ūų╣Ø(ji©”)FIFO╝░īŻ(zhu©Īn)ė├Ą─DMA ═©Ą└
· USB 2.0 ╚½╦┘(12 M▒╚╠ž/├ļ) ų„ÖC(j©®)ļpČ╦┐┌
– ļpŲ¼╔Ž╩š░l(f©Ī)Ų„(208ę²─_PQFPĘŌčbųąāH×ķę╗éĆ(g©©))
– ╝»│╔Ą─FIFO╝░īŻ(zhu©Īn)ė├Ą─DMA ═©Ą└
· USB 2.0 ╚½╦┘(12 M▒╚╠ž/├ļ) Ų„╝■Č╦┐┌
– Ų¼╔Ž╩š░l(f©Ī)Ų„Ż¼ 2-Kūų╣Ø(ji©”)┐╔┼õų├Ą─╝»│╔FIFO
· ČÓ├Į¾w┐©Įė┐┌(MCI)
– ūįäė(d©░ng)ģf(xi©”)ūh┐žųŲ╝░┐ņ╦┘ūįäė(d©░ng)öĄ(sh©┤)ō■(j©┤)é„▌ö
– ┼cMMC╝░SD┤µā”(ch©│)Ų„┐©╝µ╚▌Ż¼ų¦│ųā╔éĆ(g©©)SD┤µā”(ch©│)Ų„
· 3éĆ(g©©)═¼▓Į┤«ąą┐žųŲŲ„(SSC)
– ├┐éĆ(g©©)Įė╩šŲ„┼c░l(f©Ī)╦═Ų„ėą¬Ü(d©▓)┴óĄ─Ģr(sh©¬)ńŖ╝░ļ═¼▓Įą┼╠¢(h©żo)
– ų¦│ųI2S─ŻöMĮė┐┌Ż¼Ģr(sh©¬)ĘųÅ═(f©┤)ė├
– 32▒╚╠žĄ─Ė▀╦┘öĄ(sh©┤)ō■(j©┤)┴„é„▌ö─▄┴”
· 4éĆ(g©©)═©ė├═¼▓Į/«É▓ĮĮė╩š/░l(f©Ī)╦═Ų„(USART)
– ų¦│ųISO7816 T0/T1 ųŪ─▄┐©
– ė▓▄ø╝■╬š╩ų
– ų¦│ųRS485 ╝░Ė▀▀_(d©ó)115 KbpsĄ─IrDA ┐éŠĆ
– USART1×ķ╚½š{(di©żo)ųŲĮŌš{(di©żo)┐žųŲŠĆ
· ų„ÖC(j©®)/Å─ÖC(j©®)┤«ąą═ŌįO(sh©©)Įė┐┌(SPI)
– 8Ī½ 16 ╬╗┐╔ŠÄ│╠öĄ(sh©┤)ō■(j©┤)ķL(zh©Żng)Č╚Ż¼┐╔▀BĮė4éĆ(g©©)═ŌįO(sh©©)
· ā╔éĆ(g©©) 3 ═©Ą└16 ╬╗Č©Ģr(sh©¬)/ėŗ(j©¼)öĄ(sh©┤)Ų„(TC)
– 3éĆ(g©©)═Ō▓┐Ģr(sh©¬)ńŖ▌ö╚ļŻ¼├┐Śl═©Ą└ėą2 éĆ(g©©)ČÓ╣”─▄I/Oę²─_
– ļpPWM «a(ch©Żn)╔·Ų„Ż¼▓Č½@/▓©ą╬─Ż╩ĮŻ¼╔Ž╝ė/Ž┬£pėŗ(j©¼)öĄ(sh©┤)─▄┴”
· ā╔ŠĆĮė┐┌(TWI)
– ų„ÖC(j©®)─Ż╩Įų¦│ųŻ¼╦∙ėąā╔ŠĆAtmel EEPROM ų¦│ų
· ╦∙ėąöĄ(sh©┤)ūųę²─_Ą─IEEE 1149.1 JTAG▀ģĮńÆ▀├Ķ
· ļŖį┤╣®æ¬(y©®ng)
– VDDCOREŻ¼VDDOSC╝░VDDPLLļŖē║×ķŻ║1.65V Ī½1.95V
– VDDIOP (═ŌįO(sh©©)I/O) ╝░VDDIOM (┤µā”(ch©│)Ų„I/O)ļŖē║×ķŻ║1.65VĪ½ 3.6V
¾wŽĄ╠ž³c(di©Żn)
ĮY(ji©”)śŗ(g©░u)╠ž³c(di©Żn)
ęįARM9E-S×ķ└²ĮķĮBARM9╠Ä└ĒŲ„Ą─ų„ę¬ĮY(ji©”)śŗ(g©░u)╝░Ųõ╠ž³c(di©Żn)ĪŻARM9E-SĄ─ĮY(ji©”)śŗ(g©░u)╚ńłD4╦∙╩ŠĪŻŲõų„ę¬╠ž³c(di©Żn)╚ńŽ┬Ż║
ó┼32bitČ©³c(di©Żn)RISC╠Ä└ĒŲ„Ż¼Ė─▀M(j©¼n)ą═ARM/Thumb┤·┤aĮ╗┐ŚŻ¼į÷ÅŖ(qi©óng)ąį│╦Ę©Ų„įO(sh©©)ėŗ(j©¼)ĪŻų¦│ųīŹ(sh©¬)Ģr(sh©¬)Ż©real-timeŻ®š{(di©żo)įćŻ╗
óŲŲ¼ā╚(n©©i)ųĖ┴Ņ║═öĄ(sh©┤)ō■(j©┤)SRAMŻ¼Č°ŪęųĖ┴Ņ║═öĄ(sh©┤)ō■(j©┤)Ą─
┤µā”(ch©│)Ų„╚▌┴┐┐╔š{(di©żo)Ż╗
óŪŲ¼ā╚(n©©i)ųĖ┴Ņ║═öĄ(sh©┤)ō■(j©┤)Ė▀╦┘ŠÅø_Ų„Ż©cacheŻ®╚▌┴┐Å─4Kūų╣Ø(ji©”)ĄĮ1Mūų╣Ø(ji©”)Ż╗
ó╚įO(sh©©)ų├▒Żūo(h©┤)å╬į¬Ż©protection unitŻ®Ż¼ĘŪ│Ż▀m║Ž
ŪČ╚ļ╩Įæ¬(y©®ng)ė├ųąī”(du©¼)
┤µā”(ch©│)Ų„▀M(j©¼n)ąąĘųČ╬║═▒Żūo(h©┤)Ż╗
ó╦ų¦│ųś╦(bi©Īo)£╩(zh©│n)╗∙▒Š
▀ē▌ŗå╬į¬Æ▀├Ķ£y(c©©)įćĘĮĘ©īW(xu©”)Ż¼Č°Ūęų¦│ųBIST(built-in-self-testŻ®Ż╗
ó╠ų¦│ų
ŪČ╚ļ╩ĮĖ·█Ö
║Ļå╬į¬Ż¼ų¦│ųīŹ(sh©¬)Ģr(sh©¬)Ė·█ÖųĖ┴Ņ║═öĄ(sh©┤)ō■(j©┤)ĪŻ
ARM920T▀\(y©┤n)ąą─Ż╩Į
ARM920Tų¦│ų7ĘN▀\(y©┤n)ąą─Ż╩ĮŻ¼Ęųäe×ķŻ║
(1)ė├æ¶─Ż╩Į(usr)Ż¼
ARM╠Ä└ĒŲ„š²│ŻĄ─│╠ą“ł╠(zh©¬)ąąĀŅæB(t©żi)Ż╗
(2)┐ņ╦┘ųąöÓ─Ż╩Į (fiq)Ż¼
ė├ė┌Ė▀╦┘öĄ(sh©┤)ō■(j©┤)é„▌ö╗“═©Ą└╠Ä└ĒŻ╗
(3)═Ō▓┐ųąöÓ─Ż╩Į(irq)Ż¼
ė├ė┌═©ė├Ą─ųąöÓ╠Ä└ĒŻ╗
(4)╣▄└Ē─Ż╩Į(svc)Ż¼
▓┘ū„ŽĄĮy(t©»ng)╩╣ė├Ą─▒Żūo(h©┤)─Ż╩ĮŻ╗
(5)öĄ(sh©┤)ō■(j©┤)įLå¢(w©©n)ĮKų╣─Ż╩Į(abt)Ż¼
«ö(d©Īng)öĄ(sh©┤)ō■(j©┤)╗“ųĖ┴ŅŅA(y©┤)╚ĪĮKų╣Ģr(sh©¬)▀M(j©¼n)╚ļįō─Ż╩ĮŻ¼┐╔ė├ė┌╠ōöM┤µā”(ch©│)╝░┤µā”(ch©│)▒Żūo(h©┤)Ż╗
(6)ŽĄĮy(t©»ng)─Ż╩Į(sys)Ż¼
▀\(y©┤n)ąąŠ▀ėą╠žÖÓ(qu©ón)Ą─▓┘ū„ŽĄĮy(t©»ng)╚╬äš(w©┤)Ż╗
(7)╬┤Č©┴xųĖ┴Ņųąų╣─Ż╩Į(und)
«ö(d©Īng)╬┤Č©┴xĄ─ųĖ┴Ņł╠(zh©¬)ąąĢr(sh©¬)▀M(j©¼n)╚ļįō─Ż╩ĮŻ¼┐╔ė├ė┌ų¦│ųė▓╝■ģf(xi©”)╠Ä└ĒŲ„Ą─▄ø╝■Ę┬šµĪŻ
ARM╬ó╠Ä└ĒŲ„Ą─▀\(y©┤n)ąą─Ż╩Į┐╔ęį═©▀^(gu©░)▄ø╝■Ė─ūāŻ¼ę▓┐╔ęį═©▀^(gu©░)═Ō▓┐ųąöÓ╗“«É│Ż╠Ä└ĒĖ─ūāĪŻ┤¾ČÓöĄ(sh©┤)Ą─æ¬(y©®ng)ė├│╠ą“▀\(y©┤n)ąąį┌ė├æ¶─Ż╩ĮŽ┬Ż¼«ö(d©Īng)╠Ä└ĒŲ„▀\(y©┤n)ąąį┌ė├æ¶─Ż╩ĮŽ┬Ģr(sh©¬)Ż¼─│ą®▒╗▒Żūo(h©┤)Ą─ŽĄĮy(t©»ng)┘Yį┤╩Ū▓╗─▄▒╗įLå¢(w©©n)Ą─ĪŻ│²ė├æ¶─Ż╩Įęį═ŌŻ¼ŲõėÓĄ─6ĘN─Ż╩ĮĘQ×ķ╠žÖÓ(qu©ón)─Ż╩Į;Ųõųą│²╚źė├æ¶─Ż╩Į║═ŽĄĮy(t©»ng)─Ż╩Įęį═ŌĄ─5ĘNėųĘQ×ķ«É│Ż─Ż╩ĮŻ¼│Żė├ė┌╠Ä└ĒųąöÓ╗“«É│ŻŻ¼ęį╝░įLå¢(w©©n)╩▄▒Żūo(h©┤)Ą─ŽĄĮy(t©»ng)┘Yį┤Ą╚ŪķørĪŻ
ARM920TĄ─╣żū„ĀŅæB(t©żi)
Å─ŠÄ│╠Ą─ĮŪČ╚┐┤Ż¼ARM920T╬ó╠Ä└ĒŲ„Ą─╣żū„ĀŅæB(t©żi)ę╗░Ńėąā╔ĘNŻ║
(1)ARMĀŅæB(t©żi)Ż¼┤╦Ģr(sh©¬)╠Ä└ĒŲ„ł╠(zh©¬)ąą32╬╗Ą─Īóūųī”(du©¼)²RĄ─ARMųĖ┴ŅŻ╗
(2)ThumbĀŅæB(t©żi)Ż¼┤╦Ģr(sh©¬)╠Ä└ĒŲ„ł╠(zh©¬)ąą16╬╗Ą─Īó░ļūųī”(du©¼)²RĄ─ThumbųĖ┴ŅĪŻ
ARMųĖ┴Ņ╝»║═ThumbųĖ┴Ņ╝»Š∙ėąŪąōQ╠Ä└ĒŲ„ĀŅæB(t©żi)Ą─ųĖ┴ŅŻ¼į┌│╠ą“Ą─ł╠(zh©¬)ąą▀^(gu©░)│╠ųąŻ¼╬ó╠Ä└ĒŲ„┐╔ęįļSĢr(sh©¬)į┌ā╔ĘN╣żū„ĀŅæB(t©żi)ų«ķgŪąōQŻ¼▓óŪęŻ¼╠Ä└ĒŲ„Ą─╣żū„ĀŅæB(t©żi)Ą─▐D(zhu©Żn)ūā▓ó▓╗ė░Ēæ╠Ä└ĒŲ„Ą─╣żū„─Ż╩Į║═ŽÓæ¬(y©®ng)╝─┤µŲ„ųąĄ─ā╚(n©©i)╚▌ĪŻĄ½ARM╬ó╠Ä└ĒŲ„į┌ķ_(k©Īi)╩╝ł╠(zh©¬)ąą┤·┤aĢr(sh©¬)Ż¼æ¬(y©®ng)įō╠Äė┌ARM
ĀŅæB(t©żi)ĪŻ
«ö(d©Īng)▓┘ū„öĄ(sh©┤)╝─┤µŲ„Ą─ĀŅæB(t©żi)╬╗(╬╗0)×ķ1Ģr(sh©¬)Ż¼┐╔ęį▓╔ė├ł╠(zh©¬)ąąBXųĖ┴ŅĄ─ĘĮĘ©Ż¼╩╣╬ó╠Ä└ĒŲ„Å─
ARMĀŅæB(t©żi)ŪąōQĄĮThumbĀŅæB(t©żi)ĪŻ┤╦═ŌŻ¼«ö(d©Īng)╠Ä└ĒŲ„╠Äė┌ThumbĀŅæB(t©żi)Ģr(sh©¬)░l(f©Ī)╔·«É│Ż(╚ńIRQĪóFIQĪóUndefĪóAbortĪóSWIĄ╚)Ż¼«ö(d©Īng)«É│Ż╠Ä└ĒĘĄ╗žĢr(sh©¬)Ż¼ūįäė(d©░ng)ŪąōQ╗žThumbĀŅæB(t©żi)ĪŻ«ö(d©Īng)▓┘ū„öĄ(sh©┤)╝─┤µŲ„Ą─ĀŅæB(t©żi)╬╗×ķ0Ģr(sh©¬)Ż¼ł╠(zh©¬)ąąBXųĖ┴Ņ┐╔ęį╩╣╬ó╠Ä└ĒŲ„Å─ThumbĀŅæB(t©żi)ŪąōQĄĮARMĀŅæB(t©żi)ĪŻ┤╦═ŌŻ¼į┌╠Ä└ĒŲ„▀M(j©¼n)ąą«É│Ż╠Ä└ĒĢr(sh©¬)Ż¼īóPCųĖßś?l©©)┼╚ļ«É│Ż─Ż╩Įµ£Įė╝─┤µŲ„ųąŻ¼▓óÅ─«É│ŻŽ“┴┐ĄžųĘķ_(k©Īi)╩╝ł╠(zh©¬)ąą│╠ą“Ż¼ę▓┐╔ęį╩╣╠Ä└ĒŲ„ŪąōQĄĮARMĀŅæB(t©żi)ĪŻ
ARM920T¾wŽĄĮY(ji©”)śŗ(g©░u)Ą─┤µā”(ch©│)Ų„Ė±╩Į
ARM920T¾wŽĄĮY(ji©”)śŗ(g©░u)īó┤µā”(ch©│)Ų„┐┤ū÷╩ŪÅ─┴ŃĄžųĘķ_(k©Īi)╩╝Ą─ūų╣Ø(ji©”)Ą─ŠĆąįĮM║ŽĪŻÅ─0ūų╣Ø(ji©”)ĄĮ3ūų╣Ø(ji©”)Ę┼ų├Ą┌1éĆ(g©©)┤µā”(ch©│)Ą─ūų?j©½n)?sh©┤)ō■(j©┤)Ż¼Å─Ą┌4éĆ(g©©)ūų╣Ø(ji©”)ĄĮĄ┌7éĆ(g©©)ūų╣Ø(ji©”)Ę┼ų├Ą┌2éĆ(g©©)┤µā”(ch©│)Ą─ūų?j©½n)?sh©┤)ō■(j©┤)Ż¼ę└┤╬┼┼┴ąĪŻū„×ķ32╬╗Ą─╬ó╠Ä└ĒŲ„Ż¼ARM92OT¾wŽĄĮY(ji©”)śŗ(g©░u)╦∙ų¦│ųĄ─ūŅ┤¾īżųĘ┐šķg×ķ4GBĪŻ
ARM92OT¾wŽĄĮY(ji©”)śŗ(g©░u)┐╔ęįė├ā╔ĘNĘĮĘ©┤µā”(ch©│)ūų?j©½n)?sh©┤)ō■(j©┤)Ż¼ĘųäeĘQ×ķ┤¾Č╦Ė±╩Į║═ąĪČ╦Ė±╩ĮĪŻ┤¾Č╦Ė±╩Įųąūų?j©½n)?sh©┤)ō■(j©┤)Ą─Ė▀ūų╣Ø(ji©”)┤µā”(ch©│)į┌Ą═ĄžųĘųąŻ¼Č°ūų?j©½n)?sh©┤)ō■(j©┤)Ą─Ą═ūų╣Ø(ji©”)ät┤µĘ┼į┌Ė▀ĄžųĘųą
ęį┤¾Č╦Ė±╩Į┤µā”(ch©│)öĄ(sh©┤)ō■(j©┤)
ęįąĪČ╦Ė±╩Į┤µā”(ch©│)öĄ(sh©┤)ō■(j©┤)
ųĖ┴Ņ
ó▒loads ųĖ┴Ņ┼cn storesųĖ┴Ņ
ųĖ┴Ņų▄Ų┌öĄ(sh©┤)Ą─Ė─▀M(j©¼n)ūŅ├„’@Ą─╩ŪloadsųĖ┴Ņ║═storesųĖ┴ŅĪŻÅ─ARM7ĄĮARM9▀@ā╔ŚlųĖ┴ŅĄ─ł╠(zh©¬)ąąĢr(sh©¬)ķg£p╔┘┴╦30%ĪŻ
ųĖ┴Ņų▄Ų┌Ą─£p╔┘╩Ūė╔ė┌ARM7║═ARM9ā╔ĘN╠Ä└ĒŲ„ā╚(n©©i)Ą─ā╔éĆ(g©©)╗∙▒ŠĄ─╬ó╠Ä└ĒĮY(ji©”)śŗ(g©░u)▓╗═¼╦∙įņ│╔Ą─ĪŻ
ó┼ARM9ėą¬Ü(d©▓)┴óĄ─ųĖ┴Ņ║═öĄ(sh©┤)ō■(j©┤)
┤µā”(ch©│)Ų„Įė┐┌Ż¼į╩įS╠Ä└ĒŲ„═¼Ģr(sh©¬)▀M(j©¼n)ąą╚ĪųĖ║═ūxīæ(xi©¦)öĄ(sh©┤)ō■(j©┤)ĪŻ▀@Įąū„Ė─▀M(j©¼n)ą═
╣■ĘĮY(ji©”)śŗ(g©░u)ĪŻČ°ARM7ų╗ėąöĄ(sh©┤)ō■(j©┤)
┤µā”(ch©│)Ų„Įė┐┌Ż¼╦³═¼Ģr(sh©¬)ė├üĒ(l©ói)╚ĪųĖ┴Ņ║═öĄ(sh©┤)ō■(j©┤)įLå¢(w©©n)ĪŻ
óŲ5╝ē(j©¬)┴„╦«ŠĆę²╚ļ┴╦¬Ü(d©▓)┴óĄ─
┤µā”(ch©│)Ų„║═īæ(xi©¦)╗ž┴„╦«ŠĆŻ¼Ęųäeė├üĒ(l©ói)įLå¢(w©©n)┤µā”(ch©│)Ų„║═īóĮY(ji©”)╣¹īæ(xi©¦)╗ž
╝─┤µŲ„ĪŻ
ęį╔Žā╔³c(di©Żn)īŹ(sh©¬)¼F(xi©żn)┴╦ę╗éĆ(g©©)ų▄Ų┌═Ļ│╔loadsųĖ┴Ņ║═storesųĖ┴ŅĪŻ
ó▓╗źµi(interlocksŻ®╝╝ąg(sh©┤)
«ö(d©Īng)ųĖ┴ŅąĶꬥ─öĄ(sh©┤)ō■(j©┤)ę“?y©żn)ķęįŪ░Ą─ųĖ┴Ņø](m©”i)ėął╠(zh©¬)ąą═ĻČ°ø](m©”i)ėą£╩(zh©│n)éõ║├Š═Ģ■(hu©¼)«a(ch©Żn)╔·╣▄Ą└╗źµiĪŻ«ö(d©Īng)╣▄Ą└╗źµi░l(f©Ī)╔·Ģr(sh©¬)Ż¼ė▓╝■Ģ■(hu©¼)═Żų╣▀@éĆ(g©©)ųĖ┴ŅĄ─ł╠(zh©¬)ąąŻ¼ų▒ĄĮöĄ(sh©┤)ō■(j©┤)£╩(zh©│n)éõ║├×ķų╣ĪŻļm╚╗▀@ĘN╝╝ąg(sh©┤)Ģ■(hu©¼)į÷╝ė┤·┤ał╠(zh©¬)ąąĢr(sh©¬)ķgŻ¼Ą½╩Ū×ķ│§Ų┌Ą─įO(sh©©)ėŗ(j©¼)š▀╠ß╣®┴╦Š▐┤¾Ą─ĘĮ▒ŃĪŻŠÄūgŲ„ęį╝░ģRŠÄ│╠ą“åT┐╔ęį═©▀^(gu©░)ųžą┬įO(sh©©)ėŗ(j©¼)┤·┤aĄ─Ēśą“╗“š▀Ųõ╦¹ĘĮĘ©üĒ(l©ói)£p╔┘╣▄Ą└╗źµiĄ─öĄ(sh©┤)┴┐ĪŻ
ó│Ęųų”ųĖ┴Ņ
ARM9║═ARM7Ą─Ęųų”
ųĖ┴Ņų▄Ų┌╩ŪŽÓ═¼Ą─ĪŻČ°ŪęARM9TDMI║═ARM9E-S▓óø](m©”i)ėąī”(du©¼)Ęųų”ųĖ┴Ņ▀M(j©¼n)ąąŅA(y©┤)£y(c©©)╠Ä└ĒĪŻ
╠Ä└Ē─▄┴”
ą┬ę╗┤·Ą─ARM9╠Ä└ĒŲ„Ż¼═©▀^(gu©░)╚½ą┬Ą─įO(sh©©)ėŗ(j©¼)Ż¼▓╔ė├┴╦Ė³ČÓĄ─Š¦¾w╣▄Ż¼─▄ē“▀_(d©ó)ĄĮā╔▒Čęį╔Žė┌ARM7╠Ä└ĒŲ„Ą─╠Ä└Ē─▄┴”ĪŻ▀@ĘN╠Ä└Ē─▄┴”Ą─╠ßĖ▀╩Ū═©▀^(gu©░)į÷╝ė
Ģr(sh©¬)ńŖŅl┬╩║═£p╔┘ųĖ┴Ņł╠(zh©¬)ąąų▄Ų┌īŹ(sh©¬)¼F(xi©żn)Ą─ĪŻ
ARM7╠Ä└ĒŲ„▓╔ė├3╝ē(j©¬)┴„╦«ŠĆŻ¼Č°ARM9▓╔ė├5╝ē(j©¬)┴„╦«ŠĆĪŻį÷╝ėĄ─┴„╦«ŠĆįO(sh©©)ėŗ(j©¼)╠ßĖ▀┴╦
Ģr(sh©¬)ńŖŅl┬╩║═
▓óąą╠Ä└Ē─▄┴”ĪŻ5╝ē(j©¬)┴„╦«ŠĆ─▄ē“?q©▒)ó├┐ę╗éĆ(g©©)ųĖ┴Ņ╠Ä└ĒĘų┼õĄĮ5éĆ(g©©)
Ģr(sh©¬)ńŖų▄Ų┌ā╚(n©©i)Ż¼į┌├┐ę╗éĆ(g©©)Ģr(sh©¬)ńŖų▄Ų┌ā╚(n©©i)═¼Ģr(sh©¬)ėą5éĆ(g©©)ųĖ┴Ņį┌ł╠(zh©¬)ąąĪŻį┌═¼śėĄ─╝ė╣ż╣ż╦ćŽ┬Ż¼ARM9TDMI╠Ä└ĒŲ„Ą─Ģr(sh©¬)ńŖŅl┬╩╩ŪARM7TDMIĄ─1.8Ī½2.2▒ČĪŻ
ųĖ┴Ņų▄Ų┌Ą─Ė─▀M(j©¼n)ī”(du©¼)ė┌╠Ä└ĒŲ„ąį─▄Ą─╠ßĖ▀ėą║▄┤¾Ą─Ä═ų·ĪŻąį─▄╠ßĖ▀Ą─Ę∙Č╚ę└┘ćė┌┤·┤ał╠(zh©¬)ąąĢr(sh©¬)ųĖ┴ŅĄ─ųž»BŻ¼▀@īŹ(sh©¬)ļH╔Ž╩Ū│╠ą“▒Š╔ĒĄ─å¢(w©©n)Ņ}ĪŻī”(du©¼)ė┌▓╔ė├ūŅĖ▀╝ē(j©¬)Ą─šZ(y©│)čįŻ¼ę╗░ŃüĒ(l©ói)šf(shu©Ł)Ż¼ąį─▄Ą─╠ßĖ▀į┌30%ū¾ėęĪŻ
-
Cortex-A ŽĄ┴ą╠Ä└ĒŲ„
Cortex-A ŽĄ┴ą╠Ä└ĒŲ„╩Ūę╗ŽĄ┴ą╠Ä└ĒŲ„Ż¼ų¦│ųARM32╗“64╬╗ųĖ┴Ņ╝»Ż¼Ž“║¾═Ļ╚½
╝µ╚▌įńŲ┌Ą─ARM╠Ä└ĒŲ„Ż¼░³└©Å─1995─Ļ░l(f©Ī)▓╝Ą─ARM7TDMI╠Ä└ĒŲ„ĄĮ2002─Ļ░l(f©Ī)▓╝Ą─ARMll╠Ä└ĒŲ„ŽĄ┴ąĪŻ
║å(ji©Żn)Įķ
32╬╗RISCCPUķ_(k©Īi)░l(f©Ī)ŅI(l©½ng)ė“ųą▓╗öÓ╚ĪĄ├
═╗ŲŲŻ¼ŲõįO(sh©©)ėŗ(j©¼)Ą─╬ó╠Ä└ĒŲ„ĮY(ji©”)śŗ(g©░u)ęčĮø(j©®ng)Å─v3░l(f©Ī)š╣ĄĮ¼F(xi©żn)į┌Ą─v7ĪŻCortexŽĄ┴ą╠Ä└ĒŲ„╩Ū╗∙ė┌ARMv7╝▄śŗ(g©░u)Ą─Ż¼Ęų×ķCortex-MĪóCortex-R║═Cortex-A╚²ŅÉ(l©©i)ĪŻė╔ė┌æ¬(y©®ng)ė├ŅI(l©½ng)ė“Ą─▓╗═¼Ż¼╗∙ė┌v7╝▄śŗ(g©░u)Ą─Cortex╠Ä└ĒŲ„ŽĄ┴ą╦∙▓╔ė├Ą─╝╝ąg(sh©┤)ę▓▓╗ŽÓ═¼ĪŻ╗∙ė┌v7AĄ─ĘQ×ķ“Cortex-AŽĄ┴ąĪŻĖ▀ąį─▄Ą─
Cortex-A15Īó┐╔╔ņ┐sĄ─
Cortex-A9ĪóĮø(j©®ng)▀^(gu©░)╩ął÷(ch©Żng)“×(y©żn)ūCĄ─
Cortex-A8╠Ä└ĒŲ„ęį╝░Ė▀ą¦Ą─
Cortex-A7║═
Cortex-A5╠Ä└ĒŲ„Š∙╣▓ŽĒ═¼ę╗¾wŽĄĮY(ji©”)śŗ(g©░u)Ż¼ę“┤╦Š▀ėą═Ļš¹Ą─æ¬(y©®ng)ė├╝µ╚▌ąįŻ¼ų¦│ųé„Įy(t©»ng)Ą─ARMĪó
ThumbųĖ┴Ņ╝»║═ą┬į÷Ą─Ė▀ąį─▄Šo£Éą═Thumb-2ųĖ┴Ņ╝»ĪŻ
Cortex-A15║═Cortex-A7Č╝ų¦│ųARMv7A¾wŽĄĮY(ji©”)śŗ(g©░u)Ą─öU(ku©░)š╣Ż¼Å─Č°×ķ┤¾ą═╬’└ĒĄžųĘįLå¢(w©©n)║═ė▓╝■╠ōöM╗»ęį╝░åóė├big.LITTLE╠Ä└ĒĄ─AMBA4ACEę╗ų┬ąį╠ß╣®ų¦│ųĪŻ
ARMv7░³└©3éĆ(g©©)ĻP(gu©Īn)µIę¬╦žŻ║NEONå╬ųĖ┴ŅČÓöĄ(sh©┤)ō■(j©┤)(SIMD)å╬į¬ĪóARMtrustZone░▓╚½öU(ku©░)š╣Īóęį╝░thumb2ųĖ┴Ņ╝»Ż¼═©▀^(gu©░)16╬╗║═32╬╗╗ņ║ŽķL(zh©Żng)Č╚ųĖ┴Ņęį£pąĪ┤·┤aķL(zh©Żng)Č╚ĪŻ
Ė▀ąį─▄
Cortex-A įO(sh©©)éõ┐╔×ķŲõ─┐ś╦(bi©Īo)æ¬(y©®ng)ė├ŅI(l©½ng)ė“╠ß╣®Ė„ĘN┐╔╔ņ┐sĄ──▄ą¦ąį─▄³c(di©Żn)ĪŻę╗ą®šf(shu©Ł)├„╩Š└²╚ńŽ┬Ż║
Cortex-A15 Ż¼┐╔×ķą┬ę╗┤·ęŲäė(d©░ng)╗∙ĄA(ch©│)ĮY(ji©”)śŗ(g©░u)æ¬(y©®ng)ė├║═ę¬Ū¾┐┴┐╠Ą─¤o(w©▓)ŠĆ╗∙ĄA(ch©│)ĮY(ji©”)śŗ(g©░u)æ¬(y©®ng)ė├╠ß╣®ąį─▄ūŅĖ▀Ą─ĮŌøQĘĮ░Ė
Cortex-A7Ż¼┐╔▓╔ė├¬Ü(d©▓)┴óĪóČÓ║╦┼õų├īŹ(sh©¬)¼F(xi©żn)Ż¼╠ß╣® 800 MHz - 1.2 GHz Ą─Ąõą═Ņl┬╩Ż¼ę▓┐╔ęį┼c Cortex-A15 ĮY(ji©”)║Žė├ė┌ big.LITTLE ╠Ä└Ē
Cortex-A9 īŹ(sh©¬)¼F(xi©żn)Ż¼┐╔╠ß╣® 800 MHz - 2 GHz Ą─ś╦(bi©Īo)£╩(zh©│n)Ņl┬╩Ż¼├┐éĆ(g©©)ā╚(n©©i)║╦┐╔╠ß╣® 5000 DMIPS Ą─ąį─▄
Cortex-A8 å╬║╦ĮŌøQĘĮ░ĖŻ¼┐╔╠ß╣®Įø(j©®ng)Ø·(j©¼)ėąą¦Ą─Ė▀ąį─▄Ż¼į┌ 600 MHz - 1 GHz Ą─Ņl┬╩Ž┬Ż¼╠ß╣®Ą─ąį─▄│¼▀^(gu©░) 2000 DMIPS
Cortex-A5 Ą═│╔▒ŠīŹ(sh©¬)¼F(xi©żn)Ż¼į┌ 400- 800 MHz Ą─Ņl┬╩Ž┬Ż¼╠ß╣®Ą─ąį─▄│¼▀^(gu©░) 1200 DMIPSĪŻ
ČÓ║╦╝╝ąg(sh©┤)
Cortex-A5Īó[1] Cortex-A7ĪóCortex-A9 ║═ Cortex-A15 ╠Ä└ĒŲ„Č╝ų¦│ų ARM Ą─Ą┌Č■┤·ČÓ║╦╝╝ąg(sh©┤)
å╬║╦ĄĮ╦─║╦īŹ(sh©¬)¼F(xi©żn)Ż¼ų¦│ų├µŽ“ąį─▄Ą─æ¬(y©®ng)ė├ŅI(l©½ng)ė“ ų¦│ųī”(du©¼)ĘQ║═ĘŪī”(du©¼)ĘQĄ─▓┘ū„ŽĄĮy(t©»ng)īŹ(sh©¬)¼F(xi©żn) ═©▀^(gu©░)╝ė╦┘Ų„ę╗ų┬ąįČ╦┐┌ (ACP) į┌ī¦(d©Żo)│÷ĄĮŽĄĮy(t©»ng)Ą─š¹éĆ(g©©)╠Ä└ĒŲ„ųą▒Ż│ųę╗ų┬ąį Cortex-A7 ║═ Cortex-A15 īóČÓ║╦ę╗ų┬ąįöU(ku©░)š╣ų┴ AMBA4 ACE Ą─ 1~4 ║╦╚║╝»ęį╔ŽŻ©AMBA ę╗ų┬ąįöU(ku©░)š╣Ż®
Ė▀╝ē(j©¬)öU(ku©░)š╣
│²┴╦Š▀ėą┼c╔Žę╗┤·Įø(j©®ng)Ąõ ARM ║═ Thumb® ¾wŽĄĮY(ji©”)śŗ(g©░u)Ą─Č■▀M(j©¼n)ųŲ╝µ╚▌ąį═ŌŻ¼Cortex-A ŅÉ(l©©i)╠Ä└ĒŲ„▀Ć═©▀^(gu©░)ęįŽ┬╝╝ąg(sh©┤)öU(ku©░)š╣╠ß╣®┴╦Ė³ČÓā×(y©Łu)ä▌(sh©¼)
Thumb-2Ż¼╠ß╣®ūŅ╝č┤·┤a┤¾ąĪ║═ąį─▄
TrustZone ░▓╚½öU(ku©░)š╣Ż¼╠ß╣®┐╔ą┼ėŗ(j©¼)╦Ń
Jazelle ╝╝ąg(sh©┤)Ż¼╠ßĖ▀ł╠(zh©¬)ąąŁh(hu©ón)Š│Ż©╚ń JavaĪó.NetĪóMSILĪóPython ║═ PerlŻ®╦┘Č╚ĪŻ
«a(ch©Żn)ŲĘæ¬(y©®ng)ė├
ARM╣½╦ŠĄ─Cortex-AŽĄ┴ą╠Ä└ĒŲ„▀mė├ė┌Š▀ėąĖ▀ėŗ(j©¼)╦Ńę¬Ū¾Īó▀\(y©┤n)ąąžSĖ╗▓┘ū„ŽĄĮy(t©»ng)ęį╝░╠ß╣®Į╗╗ź├Į¾w║═łDą╬¾w“×(y©żn)Ą─æ¬(y©®ng)ė├ŅI(l©½ng)ė“ĪŻÅ─ūŅą┬╝╝ąg(sh©┤)Ą─ęŲäė(d©░ng)Internet▒žéõįO(sh©©)éõŻ©╚ń╩ųÖC(j©®)║═│¼▒ŃöyĄ─╔ŽŠW(w©Żng)▒Š╗“ųŪ─▄▒ŠŻ®ĄĮŲ¹▄ć(ch©ź)ą┼ŽóŖ╩śĘ(l©©)ŽĄĮy(t©»ng)║═Ž┬ę╗┤·öĄ(sh©┤)ūųļŖęĢŽĄĮy(t©»ng)ĪŻę▓┐╔ęįė├ė┌Ųõ╦¹ęŲäė(d©░ng)▒Ńöy╩ĮįO(sh©©)éõŻ¼▀Ć┐╔ęįė├ė┌öĄ(sh©┤)ūųļŖęĢĪóÖC(j©®)Ēö║ąĪóŲ¾śI(y©©)ŠW(w©Żng)Įj(lu©░)Īó┤“ėĪÖC(j©®)║═Ę■äš(w©┤)Ų„ĮŌøQĘĮ░ĖĪŻ▀@ę╗ŽĄ┴ąĄ─╠Ä└ĒŲ„Š▀ėąĖ▀ą¦Ą═║─Ą╚╠ž³c(di©Żn)Ż¼▒╚▌^▀m║Ž┼õų├ė┌Ė„ĘNęŲäė(d©░ng)ŲĮ┼_(t©ói)ĪŻ
ļm╚╗Cortex-A╠Ä└ĒŲ„š²│»ų°╠ß╣®═Ļ╚½Ą─Internet¾w“×(y©żn)Ą─ĘĮŽ“░l(f©Ī)š╣Ż¼Ą½Ųõæ¬(y©®ng)ė├ę▓║▄ÅVĘ║Ż¼░³└©Ż║
|
«a(ch©Żn)ŲĘŅÉ(l©©i)ą═
|
æ¬(y©®ng)ė├
|
|---|
|
|
╔ŽŠW(w©Żng)▒ŠĪóųŪ─▄▒ŠĪó▌ö╚ļ░ÕĪóļŖūėĢ°(sh©▒)ķåūxŲ„Īó╩▌┐═æ¶Č╦
|
|
╩ųÖC(j©®)
|
ųŪ─▄╩ųÖC(j©®)Īó╠ž╔½╩ųÖC(j©®)
|
|
öĄ(sh©┤)ūų╝ęļŖ
|
|
|
Ų¹▄ć(ch©ź)
|
ą┼ŽóŖ╩śĘ(l©©)Īóī¦(d©Żo)║Į
|
|
Ų¾śI(y©©)
|
╝ż╣Ō┤“ėĪÖC(j©®)Īó ┬Ęė╔Ų„Īó¤o(w©▓)ŠĆ╗∙šŠĪóVOIP ļŖįÆ║═įO(sh©©)éõ |
|
¤o(w©▓)ŠĆ╗∙ĄA(ch©│)ĮY(ji©”)śŗ(g©░u)
|
Web 2.0Īó¤o(w©▓)ŠĆ╗∙šŠĪóĮ╗ōQÖC(j©®)ĪóĘ■äš(w©┤)Ų„
|
ARM Cortex™-A5 ╠Ä└ĒŲ„╩Ū─▄ą¦ūŅĖ▀Īó│╔▒ŠūŅĄ═Ą─╠Ä└ĒŲ„Ż¼─▄ē“Ž“ūŅÅVĘ║Ą─įO(sh©©)éõ╠ß╣® Internet įLå¢(w©©n)Ż║Å─╚ļķT(m©”n)╝ē(j©¬)ųŪ─▄╩ųÖC(j©®)ĪóĄ═│╔▒Š╩ųÖC(j©®)║═ųŪ─▄ęŲäė(d©░ng)ĮKČ╦ĄĮŲš▒ķ▓╔ė├Ą─ŪČ╚ļ╩ĮĪóŽ¹┘M(f©©i)ŅÉ(l©©i)║═╣żśI(y©©)įO(sh©©)éõĪŻ
Cortex-A5 ╠Ä└ĒŲ„┐╔×ķ¼F(xi©żn)ėą ARM926EJ-S™ ║═ ARM1176JZ-S™ ╠Ä└ĒŲ„įO(sh©©)ėŗ(j©¼)╠ß╣®║▄ėąār(ji©ż)ųĄĄ─▀węŲ═ŠÅĮĪŻ╦³┐╔ęį½@Ą├▒╚ ARM1176JZ-S Ė³║├Ą─ąį─▄Ż¼▒╚ ARM926EJ-S Ė³║├Ą─╣”ą¦║═─▄ą¦ęį╝░ 100% Ą─ Cortex-A ╝µ╚▌ąįĪŻ
▀@ą®╠Ä└ĒŲ„Ž“╠žäeūóųž╣”║─║═│╔▒ŠĄ─æ¬(y©®ng)ė├│╠ą“╠ß╣®Ė▀Č╦╣”─▄Ż¼Ųõųą░³└©Ż║
ČÓųž╠Ä└Ē╣”─▄Ż¼┐╔ęį½@Ą├┐╔╔ņ┐sĪóĖ▀─▄ą¦ąį─▄
Ė▀ąį─▄ā╚(n©©i)┤µŽĄĮy(t©»ng)Ż¼░³└©Ė▀╦┘ŠÅ┤µ║═ā╚(n©©i)┤µ╣▄└Ēå╬į¬
Cortex-A7 ╠Ä└ĒŲ„
ARM Cortex™-A7 MPCore™ ╠Ä└ĒŲ„╩Ū ARM Ų∙Į±×ķų╣ķ_(k©Īi)░l(f©Ī)Ą─ūŅėąą¦Ą─æ¬(y©®ng)ė├╠Ä└ĒŲ„Ż¼╦³’@ų°öU(ku©░)š╣┴╦ ARM į┌╬┤üĒ(l©ói)╚ļķT(m©”n)╝ē(j©¬)ųŪ─▄╩ųÖC(j©®)ĪóŲĮ░ÕļŖ─Xęį╝░Ųõ╦¹Ė▀╝ē(j©¬)ęŲäė(d©░ng)įO(sh©©)éõĘĮ├µĄ─Ą═╣”║─ŅI(l©½ng)Ž╚Ąž╬╗ĪŻ
Cortex-A7 ╠Ä└ĒŲ„Ą─¾wŽĄĮY(ji©”)śŗ(g©░u)║═╣”─▄╝»┼c Cortex-A15 ╠Ä└ĒŲ„═Ļ╚½ŽÓ═¼Ż¼▓╗═¼▀@╠Äį┌ė┌Ż¼Cortex-A7 ╠Ä└ĒŲ„Ą─╬ó¾wŽĄĮY(ji©”)śŗ(g©░u)é╚(c©©)ųžė┌╠ß╣®ūŅ╝č─▄ą¦Ż¼ę“┤╦▀@ā╔ĘN╠Ä└ĒŲ„┐╔į┌
big.LITTLE┼õų├ųąģf(xi©”)═¼╣żū„Ż¼▄ø╝■┐╔ęįį┌Ė▀─▄ą¦ Cortex-A7 ╠Ä└ĒŲ„╔Ž▀\(y©┤n)ąą ę▓┐╔ęįį┌ąĶę¬Ģr(sh©¬)į┌Ė▀ąį─▄ Cortex-A15 ╠Ä└ĒŲ„╔Ž▀\(y©┤n)ąą ¤o(w©▓)ąĶųžą┬ŠÄūg,[2]
Å─Č°╠ß╣®Ė▀ąį─▄┼c│¼Ą═╣”║─Ą─ĮKśOĮM║ŽĪŻ
ū„×ķ¬Ü(d©▓)┴ó╠Ä└ĒŲ„Ż¼å╬éĆ(g©©) Cortex-A7 ╠Ä└ĒŲ„Ą──▄į┤ą¦┬╩╩Ū ARM Cortex-A8 ╠Ä└ĒŲ„Ż©ų¦│ų╚ńĮ±Ą─įSČÓūŅ┴„ąąųŪ─▄╩ųÖC(j©®)Ż®Ą─ 5 ▒ČŻ¼ąį─▄╠ß╔² 50%Ż¼Č°│▀┤ńāH×ķ║¾š▀Ą─╬ÕĘųų«ę╗ĪŻ
Cortex-A7 ┐╔ęį╩╣ 2013-2014 ─ĻŲ┌ķgĄ═ė┌ 100 ├└į¬ār(ji©ż)Ė±³c(di©Żn)Ą─╚ļķT(m©”n)╝ē(j©¬)ųŪ─▄╩ųÖC(j©®)┼c 2010 ─Ļ 500 ├└į¬Ą─Ė▀Č╦ųŪ─▄╩ųÖC(j©®)ŽÓµŪ├└ĪŻ▀@ą®╚ļķT(m©”n)╝ē(j©¬)ųŪ─▄╩ųÖC(j©®)į┌░l(f©Ī)š╣ųą╩└Įńīóųžą┬Č©┴x▀BĮė║═ Internet ╩╣ė├ĪŻ
įō╠Ä└ĒŲ„┼cŲõ╦¹ Cortex-A ŽĄ┴ą╠Ä└ĒŲ„═Ļ╚½╝µ╚▌▓óš¹║Ž┴╦Ė▀ąį─▄ Cortex-A15 ╠Ä└ĒŲ„Ą─╦∙ėą╣”─▄Ż¼░³└©╠ōöM╗»Īó┤¾╬’└ĒĄžųĘöU(ku©░)š╣ (LPAE) NEON Ė▀╝ē(j©¬) SIMD ║═ AMBA 4 ACE ę╗ų┬ąįĪŻ
ūŅ╝čĄ─╣”ą¦║═š╝ė├┐šķgŻ¼┐╔ū„×ķ¬Ü(d©▓)┴óĄ─æ¬(y©®ng)ė├╠Ä└ĒŲ„ ąį─▄Ė▀ė┌ 2011 ─Ļų„┴„ųŪ─▄╩ųÖC(j©®) CPU ąį─▄╠ß╔²Ė▀▀_(d©ó) 20% Č°╣”║─ĮĄĄ═ 60%AMBA 4 ACE ę╗ų┬ąįĮė┐┌ų¦│ų┤¾ąĪ CPU ╚║╝»ų«ķg 20us ęįŽ┬Ą─╔ŽŽ┬╬─▀węŲ
ARMCortex-A8╠Ä└ĒŲ„╩Ūę╗┐Ņ▀mė├ė┌Å═(f©┤)ļs▓┘ū„ŽĄĮy(t©»ng)╝░ė├æ¶æ¬(y©®ng)ė├Ą─æ¬(y©®ng)ė├╠Ä└ĒŲ„Ż¼ŲõĮY(ji©”)śŗ(g©░u)╚ńłD╦∙╩ŠĪŻų¦│ųųŪ─▄─▄į┤╣▄└Ē(IEMŻ¼IntelligentEnergyManger)╝╝ąg(sh©┤)Ą─ARMArtisanÄņ(k©┤)ęį╝░Ž╚▀M(j©¼n)Ą─ą╣┬®┐žųŲ╝╝ąg(sh©┤)Ż¼╩╣Ą├Cortex-A8╠Ä└ĒŲ„īŹ(sh©¬)¼F(xi©żn)┴╦ĘŪĘ▓Ą─╦┘Č╚║═╣”║─ą¦┬╩į┌65nm╔Ž╦ćŽ┬Ż¼ARMcortex-A8╠Ä└ĒŲ„Ą─╣”║─▓╗ĄĮ300mWŻ¼─▄ē“╠ß╣®Ė▀ąį─▄║═Ą═╣”║─╦³Ą┌ę╗┤╬×ķĄ═┘M(f©©i)ė├ĪóĖ▀╚▌┴┐Ą─«a(ch©Żn)ŲĘĦüĒ(l©ói)┴╦┼_(t©ói)╩ĮÖC(j©®)╝ē(j©¬)äeĄ─ąį─▄
A8╠Ä└ĒŲ„ĮY(ji©”)śŗ(g©░u)
Cortex-A8╠Ä└ĒŲ„╩ŪĄ┌ę╗┐Ņ╗∙ė┌Ž┬ę╗┤·ARMv7╝▄śŗ(g©░u)Ą─æ¬(y©®ng)ė├╠Ä└ĒŲ„Ż¼╩╣ė├┴╦─▄ē“ĦüĒ(l©ói)Ė³Ė▀ąį─▄ĪóĖ³Ą═╣”║─║═Ė³Ė▀┤·┤a├▄Č╚Ą─Thumb-2╝╝ąg(sh©┤)╦³╩ū┤╬▓╔ė├┴╦ÅŖ(qi©óng)┤¾Ą─NEONą┼╠¢(h©żo)╠Ä└ĒöU(ku©░)š╣╝»Ż¼×ķH.264║═MP3Ą╚├Į¾wŠÄĮŌ┤a╠ß╣®╝ė╦┘
Cortex-A8Ą─ĮŌøQĘĮ░Ė▀Ć░³└©Jazelle-RCTJava╝ė╦┘╝╝ąg(sh©┤)Ż¼ī”(du©¼)īŹ(sh©¬)Ģr(sh©¬)(JIT)║═äė(d©░ng)æB(t©żi)š{(di©żo)š¹ŠÄūg(DAC)╠ß╣®ūŅā×(y©Łu)╗»Ż¼═¼Ģr(sh©¬)£p╔┘ā╚(n©©i)┤µš╝ė├┐šķgĖ▀▀_(d©ó)3▒Čįō╠Ä└ĒŲ„┼õų├┴╦Ž╚▀M(j©¼n)Ą─│¼ś╦(bi©Īo)┴┐¾wŽĄĮY(ji©”)śŗ(g©░u)┴„╦«ŠĆŻ¼─▄ē“═¼Ģr(sh©¬)ł╠(zh©¬)ąąČÓŚlųĖ┴ŅŻ¼▓óŪę╠ß╣®│¼▀^(gu©░)2.0DMIPS/MHzĄ─ąį─▄╠Ä└ĒŲ„╝»│╔┴╦ę╗éĆ(g©©)┐╔š{(di©żo)│▀┤ńĄ─Č■╝ē(j©¬)Ė▀╦┘ŠÅø_┤µā”(ch©│)Ų„Ż¼─▄ē“═¼Ė▀╦┘Ą─16KB╗“š▀32KBę╗╝ē(j©¬)Ė▀╦┘ŠÅø_┤µā”(ch©│)Ų„ę╗Ų╣żū„Ż¼Å─Č°▀_(d©ó)ĄĮūŅ┐ņĄ─ūx╚Ī╦┘Č╚║═ūŅ┤¾Ą─═╠═┬┴┐ą┬╠Ä└ĒŲ„▀Ć┼õų├┴╦ė├ė┌░▓╚½Į╗ęū║═öĄ(sh©┤)ūų░µÖÓ(qu©ón)╣▄└ĒĄ─TrustZone╝╝ąg(sh©┤)Ż¼ęį╝░īŹ(sh©¬)¼F(xi©żn)Ą═╣”║─╣▄└ĒĄ─IEM╣”─▄
Cortex-A8╠Ä└ĒŲ„╩╣ė├┴╦Ž╚▀M(j©¼n)Ą─Ęųų¦ŅA(y©┤)£y(c©©)╝╝ąg(sh©┤)Ż¼▓óŪęŠ▀ėąīŻ(zhu©Īn)ė├Ą─NEONš¹ą═║═ĖĪ³c(di©Żn)ą═┴„╦«ŠĆ▀M(j©¼n)ąą├Į¾w║═ą┼╠¢(h©żo)╠Ä└Ēį┌╩╣ė├ąĪė┌4mm2Ą─╣ĶŲ¼╝░Ą═╣”║─Ą─65nm╣ż╦ćĄ─ŪķørŽ┬Ż¼Cortex-A8╠Ä└ĒŲ„Ą─▀\(y©┤n)ąąŅl┬╩īóĖ▀ė┌600MHz(▓╗░³└©NEONūĘ█Ö╝╝ąg(sh©┤)║═Č■╝ē(j©¬)Ė▀╦┘ŠÅø_┤µā”(ch©│)Ų„)į┌Ė▀ąį─▄Ą─90nm║═65nm╣ż╦ćŽ┬Ż¼Cortex-A8╠Ä└ĒŲ„▀\(y©┤n)ąąŅl┬╩ūŅĖ▀┐╔▀_(d©ó)1GHzŻ¼─▄ē“ØMūŃĖ▀ąį─▄Ž¹┘M(f©©i)«a(ch©Żn)ŲĘįO(sh©©)ėŗ(j©¼)Ą─ąĶę¬ĪŻ
Cortex-A9╠Ä└ĒŲ„
ARM Cortex™-A9 ╠Ä└ĒŲ„╠ß╣®┴╦╩ʤo(w©▓)Ū░└²Ą─Ė▀ąį─▄║═Ė▀─▄ą¦Ż¼Å─Č°╩╣Ųõ│╔×ķąĶę¬į┌Ą═╣”║─╗“╔ó¤ß╩▄Ž▐Ą─│╔▒Š├¶Ėąą═įO(sh©©)éõųą╠ß╣®Ė▀ąį─▄Ą─įO(sh©©)ėŗ(j©¼)Ą─└ĒŽļĮŌøQĘĮ░ĖĪŻ ╦³╝╚┐╔ė├ū„å╬║╦╠Ä└ĒŲ„Ż¼ę▓┐╔ė├ū„┐╔┼õų├Ą─ČÓ║╦╠Ä└ĒŲ„Ż¼═¼Ģr(sh©¬)┐╔╠ß╣®┐╔║Ž│╔╗“ė▓║ĻīŹ(sh©¬)¼F(xi©żn)ĪŻįō╠Ä└ĒŲ„▀mė├ė┌Ė„ĘNæ¬(y©®ng)ė├ŅI(l©½ng)ė“Ż¼Å─Č°─▄ē“?q©▒)”ČÓéĆ(g©©)╩ął÷(ch©Żng)▀M(j©¼n)ąąĘĆ(w©¦n)Č©Ą─▄ø╝■═Č┘YĪŻ
┼cĖ▀ąį─▄ėŗ(j©¼)╦ŃŲĮ┼_(t©ói)Ž¹║─Ą─╣”┬╩ŽÓ▒╚Ż¼ARM Cortex-A9 ╠Ä└ĒŲ„┐╔╠ß╣®╣”┬╩Ė³Ą═Ą─ū┐įĮ╣”─▄Ż¼Ųõųą░³└©Ż║
¤o(w©▓)┼céÉ▒╚Ą─ąį─▄Ż¼2GHz ś╦(bi©Īo)£╩(zh©│n)▓┘ū„┐╔╠ß╣® TSMC 40G ė▓║ĻīŹ(sh©¬)¼F(xi©żn)
ęįĄ═╣”║─×ķ─┐ś╦(bi©Īo)Ą─å╬║╦īŹ(sh©¬)¼F(xi©żn)Ż¼├µŽ“│╔▒Š├¶Ėąą═įO(sh©©)éõ
└¹ė├Ė▀╝ē(j©¬) MPCore ╝╝ąg(sh©┤)Ż¼ūŅČÓ┐╔öU(ku©░)š╣×ķ 4 éĆ(g©©)ę╗ų┬Ą─ā╚(n©©i)║╦
Cortex-A15 ╠Ä└ĒŲ„
ARM Cortex™-A15 MPCore™ ╠Ä└ĒŲ„╩Ūąį─▄Ė▀Ūę┐╔╩┌ėĶįS┐╔Ą─╠Ä└ĒŲ„ĪŻ╦³╠ß╣®Ū░╦∙╬┤ėąĄ─╠Ä└Ē╣”─▄Ż¼┼cĄ═╣”║─╠žąįŽÓĮY(ji©”)║ŽŻ¼į┌Ė„ĘN╩ął÷(ch©Żng)╔Ž│╔Š═┴╦ū┐įĮĄ─«a(ch©Żn)ŲĘŻ¼░³└©ųŪ─▄╩ųÖC(j©®)ĪóŲĮ░ÕļŖ─XĪóęŲäė(d©░ng)ėŗ(j©¼)╦ŃĪóĖ▀Č╦öĄ(sh©┤)ūų╝ęļŖĪóĘ■äš(w©┤)Ų„║═¤o(w©▓)ŠĆ╗∙ĄA(ch©│)ĮY(ji©”)śŗ(g©░u)ĪŻCortex-A15 MPCore ╠Ä└ĒŲ„╠ß╣®┴╦ąį─▄Īó╣”─▄║═─▄ą¦Ą─¬Ü(d©▓)╠žĮM║ŽŻ¼▀M(j©¼n)ę╗▓Į╝ėÅŖ(qi©óng)┴╦ ARM į┌▀@ą®Ė▀ār(ji©ż)ųĄ║═Ė▀╚▌┴┐æ¬(y©®ng)ė├╝Ü(x©¼)Ęų╩ął÷(ch©Żng)ųąĄ─ŅI(l©½ng)ī¦(d©Żo)Ąž╬╗ĪŻ
Cortex-A15 MPCore ╠Ä└ĒŲ„╩Ū Cortex-A ŽĄ┴ą╠Ä└ĒŲ„Ą─ūŅą┬│╔åTŻ¼┤_▒Żį┌æ¬(y©®ng)ė├ĘĮ├µ┼c╦∙ėąŲõ╦¹½@Ą├Ė▀Č╚┘Øūu(y©┤)Ą─ Cortex-A ╠Ä└ĒŲ„═Ļ╚½╝µ╚▌ĪŻ▀@śėŻ¼Š═┐╔ęį┴ó╝┤įLå¢(w©©n)ęčĄ├ĄĮšJ(r©©n)┐╔Ą─ķ_(k©Īi)░l(f©Ī)ŲĮ┼_(t©ói)║═▄ø╝■¾wŽĄŻ¼░³└© Android™ĪóAdobe® Flash® PlayerĪóJava Platform Standard Edition (Java SE)ĪóJavaFXĪóLinuxĪóMicrosoft Windows EmbeddedĪóSymbian ║═ Ubuntu ęį╝░ 700 ČÓéĆ(g©©) ARM Connected Community™ │╔åTŻ¼▀@ą®│╔åT╠ß╣®æ¬(y©®ng)ė├▄ø╝■Īóė▓╝■║═▄ø╝■ķ_(k©Īi)░l(f©Ī)╣żŠ▀Īóųąķg╝■ęį╝░ SoC įO(sh©©)ėŗ(j©¼)Ę■äš(w©┤)ĪŻ
Cortex-A15 MPCore ╠Ä└ĒŲ„Š▀ėą¤o(w©▓)ą“│¼ś╦(bi©Īo)┴┐╣▄Ą└Ż¼Ä¦ėąŠo├▄±Ņ║ŽĄ─Ą═čė▀t 2 ╝ē(j©¬)Ė▀╦┘ŠÅ┤µŻ¼įōĖ▀╦┘ŠÅ┤µĄ─┤¾ąĪūŅĖ▀┐╔▀_(d©ó) 4MBĪŻ
ĖĪ³c(di©Żn)║═ NEON™ ├Į¾wąį─▄ĘĮ├µĄ─Ųõ╦¹Ė─▀M(j©¼n)╩╣įO(sh©©)éõ─▄ē“?y©żn)ķŽ¹┘M(f©©i)š▀╠ß╣®Ž┬ę╗┤·ė├涾w“×(y©żn)Ż¼▓ó×ķ Web ╗∙ĄA(ch©│)ĮY(ji©”)śŗ(g©░u)æ¬(y©®ng)ė├╠ß╣®Ė▀ąį─▄ėŗ(j©¼)╦ŃĪŻ
ŅA(y©┤)ėŗ(j©¼) Cortex-A15 MPCore ╠Ä└ĒŲ„Ą─ęŲäė(d©░ng)┼õų├╦∙─▄╠ß╣®Ą─ąį─▄╩Ū«ö(d©Īng)Ū░Ą─Ė▀╝ē(j©¬)ųŪ─▄╩ųÖC(j©®)ąį─▄Ą─╬Õ▒Č▀ĆČÓĪŻį┌Ė▀╝ē(j©¬)╗∙ĄA(ch©│)ĮY(ji©”)śŗ(g©░u)æ¬(y©®ng)ė├ųąŻ¼Cortex-A15 Ą─▀\(y©┤n)ąą╦┘Č╚ūŅĖ▀┐╔▀_(d©ó) 2.5GHzŻ¼▀@īóų¦│ųį┌▓╗öÓĮĄĄ═╣”║─Īó╔ó¤ß║═│╔▒ŠŅA(y©┤)╦ŃĘĮ├µīŹ(sh©¬)¼F(xi©żn)Ė▀Č╚┐╔╔ņ┐sĄ─ĮŌøQĘĮ░ĖĪŻ
Cortex-A57
cortex-a57╩ŪARMßśī”(du©¼)2013─ĻĪó2014─Ļ║═2015─ĻįO(sh©©)ėŗ(j©¼)Ų³c(di©Żn)Ą─CPU«a(ch©Żn)ŲĘŽĄ┴ąĄ─Ųņ┼×╝ē(j©¬)CPUŻ¼╦³▓╔ė├armv8-a╝▄śŗ(g©░u)Ż¼╠ß╣®64╬╗╣”─▄Ż¼Č°Ūę═©▀^(gu©░)Aarch32ł╠(zh©¬)ąąĀŅæB(t©żi)Ż¼▒Ż│ų┼cARMv7╝▄śŗ(g©░u)Ą─═Ļ╚½║¾Ž“╝µ╚▌ąįĪŻį┌Ė▀ė┌4GBĄ─ā╚(n©©i)┤µÅVĘ║╩╣ė├ų«Ū░Ż¼64╬╗▓ó▓╗╩ŪęŲäė(d©░ng)ŽĄĮy(t©»ng)šµš²▒žąĶĄ─Ż¼╝┤▒ŃĄĮ─ŪĢr(sh©¬)ę▓┐╔ęį╩╣ė├öU(ku©░)š╣╬’└ĒīżųĘ╝╝ąg(sh©┤)üĒ(l©ói)ĮŌøQŻ¼Ą½▒Mįń═Ų│÷64╬╗Ż¼┐╔ęįīŹ(sh©¬)¼F(xi©żn)Ė³ķL(zh©Żng)ĪóĖ³ĒśĢ│Ą─▄ø╝■▀węŲŻ¼ūīĖ▀ąį─▄æ¬(y©®ng)ė├│╠ą“─▄ē“│õĘų└¹ė├Ė³┤¾╠ōöMĄžųĘĘČć·üĒ(l©ói)▀\(y©┤n)ąąā╚(n©©i)╚▌äō(chu©żng)Į©æ¬(y©®ng)ė├│╠ą“Ż¼└²╚ńęĢŅlŠÄ▌ŗĪóššŲ¼ŠÄ▌ŗ║═į÷ÅŖ(qi©óng)¼F(xi©żn)īŹ(sh©¬)ĪŻą┬╝▄śŗ(g©░u)┐╔ęį▀\(y©┤n)ąą64╬╗▓┘ū„ŽĄĮy(t©»ng)Ż¼▓óį┌▓┘ū„ŽĄĮy(t©»ng)╔Ž¤o(w©▓)┐p╗ņ║Ž▀\(y©┤n)ąą32╬╗║═64╬╗æ¬(y©®ng)ė├│╠ą“ĪŻARMv8╝▄śŗ(g©░u)┐╔ęįīŹ(sh©¬)¼F(xi©żn)ĀŅæB(t©żi)ų«ķgĄ─▌p╦╔▐D(zhu©Żn)ōQĪŻ
│²┴╦ARMv8Ą─╝▄śŗ(g©░u)ā×(y©Łu)ä▌(sh©¼)ų«═ŌŻ¼Cortex-A57▀Ć╠ßĖ▀┴╦å╬éĆ(g©©)Ģr(sh©¬)ńŖų▄Ų┌ąį─▄Ż¼▒╚Ė▀ąį─▄Ą─Cortex-A15CPUĖ▀│÷┴╦20%ų┴40%ĪŻ╦³▀ĆĖ─▀M(j©¼n)┴╦Č■╝ē(j©¬)Ė▀╦┘ŠÅ┤µĄ─Ą─įO(sh©©)ėŗ(j©¼)ęį╝░ā╚(n©©i)┤µŽĄĮy(t©»ng)Ą─Ųõ╦¹ĮM╝■Ż¼śO┤¾Ą─╠ßĖ▀┴╦─▄ą¦ĪŻCortex-A57īó×ķęŲäė(d©░ng)ŽĄĮy(t©»ng)╠ß╣®Ū░╦∙╬┤ėąĄ─Ė▀─▄ą¦ąį─▄╦«ŲĮŻ¼Č°ĮĶų·big.LITTLEŻ¼SoC─▄ęį║▄Ą═Ą─ŲĮŠ∙╣”║─ū÷ĄĮ▀@ę╗³c(di©Żn)ĪŻ
Cortex-A72╩ŪARMąį─▄ūŅ│÷╔½ĪóūŅŽ╚▀M(j©¼n)Ą─╠Ä└ĒŲ„ĪŻė┌2015─Ļ─Ļ│§š²╩Į░l(f©Ī)▓╝Ą─Cortex-A72╩Ū╗∙ė┌ARMv8-A╝▄śŗ(g©░u)Īó▓óśŗ(g©░u)Į©ė┌Cortex-A57╠Ä└ĒŲ„į┌ęŲäė(d©░ng)║═Ų¾śI(y©©)įO(sh©©)éõŅI(l©½ng)ė“│╔╣”Ą─╗∙ĄA(ch©│)ų«╔ŽĪŻį┌ŽÓ═¼Ą─ęŲäė(d©░ng)įO(sh©©)éõļŖ│žē█├³Ž▐ųŲŽ┬Ż¼Cortex-A72─▄ŽÓ▌^╗∙ė┌Cortex-A15Ą─įO(sh©©)éõ╠ß╣®3.5▒ČĄ─ąį─▄▒Ē¼F(xi©żn)Ż¼š╣¼F(xi©żn)ā×(y©Łu)«ÉĄ─š¹¾w╣”║─ą¦┬╩ĪŻ
Cortex-A72Ą─ÅŖ(qi©óng)╗»ąį─▄║═╣”║─╦«ŲĮųžą┬Č©┴x┴╦2016─ĻĖ▀Č╦įO(sh©©)éõ×ķŽ¹┘M(f©©i)š▀ĦüĒ(l©ói)Ą─žSĖ╗▀BĮė║═ŪķŠ│Ėąų¬Ż©context-awareŻ®Ą─¾w“×(y©żn)Ż¼▀@ą®Ė▀Č╦įO(sh©©)éõ║Ł╔wĖ▀ļAĄ─ųŪ─▄╩ųÖC(j©®)Īóųąą═ŲĮ░ÕļŖ─XĪó┤¾ą═ŲĮ░ÕļŖ─XĪóĘŁ╔w╩Į╣Pėø▒ŠĪóę╗ų▒ĄĮ═Ōą╬ęÄ(gu©®)Ė±┐╔ūā╗»Ą─ęŲäė(d©░ng)įO(sh©©)éõĪŻ╬┤üĒ(l©ói)Ą─Ų¾śI(y©©)╗∙šŠ║═Ę■äš(w©┤)Ų„ąŠŲ¼ę▓─▄╩▄╗▌ė┌Cortex-A72Ą─ąį─▄Ż¼▓óį┌Ųõā×(y©Łu)«ÉĄ──▄ą¦╗∙ĄA(ch©│)╔ŽŻ¼į┌ėąŽ▐Ą─╣”║─ĘČć·ā╚(n©©i)į÷╝ėā╚(n©©i)║╦öĄ(sh©┤)┴┐Ż¼╠ß╔²╣żū„žō(f©┤)▌d┴┐ĪŻ
Cortex-A72┐╔į┌ąŠŲ¼╔Žå╬¬Ü(d©▓)īŹ(sh©¬)¼F(xi©żn)Ż¼ę▓┐╔ęį┤Ņ┼õCortex-A53╠Ä└ĒŲ„┼cARMCoreLinkTMCCIĖ▀╦┘ŠÅ┤µę╗ų┬ąį╗ź▀BŻ©CacheCoherentInterconnectŻ®śŗ(g©░u)│╔ARMbig.LITTLETM┼õų├Ż¼▀M(j©¼n)ę╗▓Į╠ß╔²─▄ą¦ĪŻ
Cortex-A72╩Ū─┐Ū░╗∙ė┌ARMv8-A╝▄śŗ(g©░u)╠Ä└ĒŲ„ųąąį─▄ūŅĖ▀Ą─╠Ä└ĒŲ„ĪŻ╦³į┘┤╬š╣¼F(xi©żn)┴╦ARMį┌╠Ä└ĒŲ„╝╝ąg(sh©┤)Ą─ŅI(l©½ng)Ž╚Ąž╬╗Ż¼į┌╠ß╔²ą┬Ą─ąį─▄ś╦(bi©Īo)£╩(zh©│n)ų«ėÓŻ¼═¼Ģr(sh©¬)┤¾Ę∙ĮĄĄ═╣”║─Ż¼┐╔ÅVĘ║Ąž?c©ói)U(ku©░)š╣æ¬(y©®ng)ė├ė┌ęŲäė(d©░ng)┼cŲ¾śI(y©©)įO(sh©©)éõĪŻ
ųŪ─▄╩ųÖC(j©®)╩Ū─┐Ū░┤¾▒Ŗų„ꬥ─ėŗ(j©¼)╦ŃŲĮ┼_(t©ói)Ż¼╠ß╣®╩╣ė├š▀ļSĢr(sh©¬)ļSĄžäō(chu©żng)įņĪóÅŖ(qi©óng)╗»ęį╝░╩╣ė├ā╚(n©©i)╚▌Ą─╣”─▄ĪŻöMšµŪęÅ═(f©┤)ļsĄ─łDŽ±┼cęĢŅl▓ČūĮĪóų„ÖC(j©®)╝ē(j©¬)ė╬æ“░ŃĄ─ąį─▄Īóė├üĒ(l©ói)▀M(j©¼n)ąą╬─Ön┼c▐k╣½æ¬(y©®ng)ė├┴„Ģ│╠Ä└ĒĄ─╔·«a(ch©Żn)┴”╠ū╝■Ą╚Ż¼▀@ą®ąĶŪ¾┤┘╩╣Cortex-A72╚ń┤╦Ė▀Č╦ąį─▄Ą─╠Ä└ĒŲ„├µ╩ąŻ¼ł╠(zh©¬)ąą▀@ą®Ę■äš(w©┤)Ą─įO(sh©©)éõ▒╗ę¬Ū¾į┌Ė³▌p▒ĪĪóĖ³Ģr(sh©¬)╔ąĄ─═Ōą╬įO(sh©©)ėŗ(j©¼)ų«Ž┬Ż¼▒žĒÜ╚½╠ņ║“╠Ä└Ē╚šęµį÷ķL(zh©Żng)Ą─CPU║═GPU╣żū„žō(f©┤)▌dŻ¼▀@╩╣Ą├ųŲįņ╔╠▓╗Ą├▓╗īóŠ½┴”ė├į┌īżšęĖ▀─▄ą¦Ą─╠Ä└ĒŲ„ā╚(n©©i)║╦ĪŻį┌ųŪ─▄╩ųÖC(j©®)ĪóŲĮ░ÕļŖ─XĪó╔§ų┴╩Ū┤¾│▀┤ńĄ─ęŲäė(d©░ng)įO(sh©©)éõŻ¼Cortex-A72─▄═©▀^(gu©░)│÷╔½Ą──▄ą¦┼cā╚(n©©i)┤µŽĄĮy(t©»ng)Ż¼╠ß╣”Į^╝čĄ─ė├涾w“×(y©żn)ĪŻīóCortex-A72┼cCortex-A53╠Ä└ĒŲ„ęįARMbig.LITTLE™Ż©┤¾ąĪ║╦Ż®╠Ä└ĒŲ„▀M(j©¼n)ąą┼õų├Ż¼┐╔ęįöU(ku©░)š╣š¹¾wĄ─ąį─▄┼cą¦┬╩▒Ē¼F(xi©żn)ĪŻ






ŽĄ┐═Ę■")
ŽĄ┐═Ę■")
ŽĄ┐═Ę■")
ŽĄ┐═Ę■")
